Transformers
In this blog post, I will be exploring the Transformer architecture. To demonstrate its application, I’ll be building a sequence classifier and text generation using Transformers.
Introduction
Transformers are a very exciting family of machine learning architectures. It comes with great capability in handling long-range dependencies thanks to its special design of positional encoding, self-attention mechanism and encoder-decoder architecture.
Method
Self-attention
The fundamental operation of any transformer architecture is the self-attention operation. With the help of the attention, the dependencies between source and target sequences are not restricted by the in-between distance anymore. Calculating attention comes primarily in three steps. First, we take the query and each key and compute the similarity between the two to obtain a weight. Frequently used similarity functions is the dot product. The second step is typically to use a softmax function to normalize these weights, and finally to weight these weights in conjunction with the corresponding values and obtain the final Attention.
In a single self-attention operation, all this information just gets summed together. In other words, word can mean different things to different neighbours that has not been taken into consideration. The self-attention can be improved with greater power of discrimination, by combining several self attention mechanisms. This process is called multi-head self-attention. There are two ways to apply multi-head self-attention namely narrow and wide self-attention.
Transformers Block
A transformer is not just a self-attention layer, it is an architecture. There are some variations on how to build a basic transformer block, but most of them are structured roughly like in a sequence: a self attention layer, layer normalization, a feed forward layer (a single MLP applied independently to each vector), and another layer normalization. Residual connections are added around both, before the normalization. The order of the various components is not set in stone; the important thing is to combine self-attention with a local feedforward, and to add normalization and residual connections.
Dataset overview
IMDB Dataset:
The core dataset contains 50,000 reviews split evenly into 25k train and 25k test sets. The overall distribution of labels is balanced (25k pos and 25k neg). In the labeled train/test sets, a negative review has a score <= 4 out of 10, and a positive review has a score >= 7 out of 10.
Wikipedia Dataset:
The online encyclopedia Wikipedia is a good snapshot of the Human World Knowledge. enwik9 contains 10^9 characters of Wikipedia text. The data is UTF-8 encoded XML consisting primarily of English text. enwik9 contains 243,426 article titles, of which 85,560 are #REDIRECT to fix broken links, and the rest are regular articles.
Experiment
The heart of the architecture used for both that the tasks will simply be a large chain of transformer blocks.
Sequence Classification
The input is represented using word embedding and position embedding to have at least some sensitivity to word order. Six block of transformers are used. At depth 6, with a maximum sequence length of 512 is fixed. The output sequence is averaged to produce a single vector representing the whole sequence. This vector is projected down to a vector with one element per class and softmaxed to produce probabilities.
 Sequence classifier transformer [1]
Sequence classifier transformer [1]
Due to resource constraints, this transformer achieves an accuracy of about 50% with 10 epochs. To see the real near-human performance of transformers, we’d need to increase the number of epochs and train a much deeper model on much more data.
Text Generation
The trick used here is autoregressive model. The training regime is simple (and has been around for far longer than transformers have). A sequence is given as a input to sequence-to-sequence model which predicts the next character at each point in the sequence. In other words, the target output is the same sequence shifted one character to the left. Typically, the same thing can be achieved using RNN but they cannot look forward into the input sequence: output i depends only on inputs 0 to i. With a transformer, the output depends on the entire input sequence, so prediction of the next character becomes vacuously easy, just retrieve it from the input. To use self-attention as an autoregressive model, we’ll need to ensure that it cannot look forward into the sequence. This is realized by applying a mask to the matrix of dot products, before the softmax is applied. This mask disables all elements above the diagonal of the matrix.
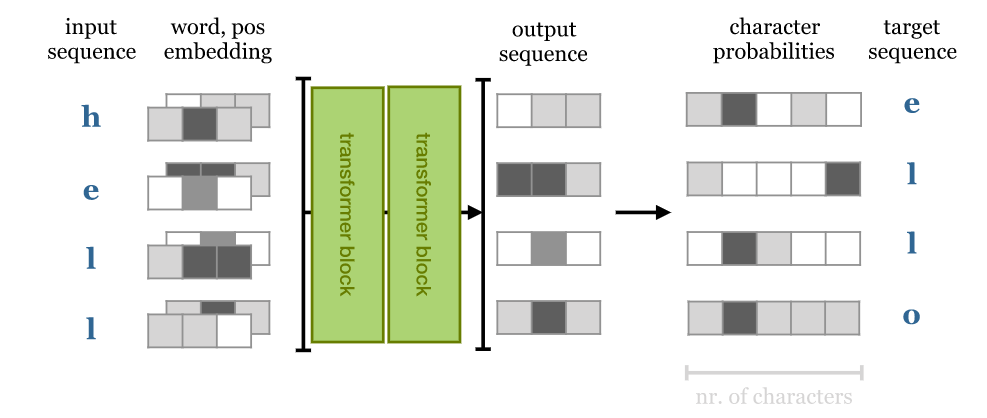 Text generation transformer [1]
Text generation transformer [1]
The model trains on sequences of length 256, using 12 transformer blocks and 256 embedding dimension. The model generate output from a 256-character seed: for each character, the preceding 256 characters is feed as input to predict the next character (the last output vector). We sample from that with a temperature of 0.5, and move to the next character. At this point, the model achieves a compression of 1.9722 bits per byte on the validation set with 10 epochs. The compression can be brought further down with more number of epochs.
Output
Sequence Classification
Input
If you're going to watch this movie, avoid any spoilers, even spoiler free reviews. Which is why I'm not going to say anything about the movie. Not even my opinion. All I'm going to say is: The crowd applauded 3 times during the movie, and stood up to clap their hands after. This I have never witnessed in a Dutch cinema. Dutch crowds aren't usually passionate about this. I checked the row where I was sitting, and people were crying. After the movie, I was seeing people with smudged mascara. That's all I have to say about the movie.
Output
1
2
probabilities... tensor([[-1.9710, -0.1500]])
pos
Text Generation
Input
1228X Human & Rousseau. Because many of his stories were originally published in long-forgotten magazines and journals, there are a number of [[anthology|anthologies]] by different collators each containing a different selection. His original books ha
Output
1
ve long the book of his containing and his in control miniming the minimidial to strong of the [[John Anthology]] official different of the Singholy and other Control and the [[Singhology of Control]]. These the [[Controlland Controlland]] in [[Singhology]], and it it is one of the [[United States]]. The present of the changes of the [[George Last of Controlland]] in [[1925]] speed and [[1978]] had and many when he most is often in the [[1990s]] with a [[controlland]] of the [[Singholand Controlland]] ([[1960]]) the [[Theology of the [[Jases American]] was of the [[France]] and [[1948]] and [[
Code
The complete code used in this post can be found in my Github repo.