Understanding Byte-Pair Encoding (BPE) - From Language to Tokens
In the world of machine learning and natural language processing, one of the fundamental challenges is converting human language into a format that computers can understand and process. This is where tokenization comes in, and specifically, a clever algorithm called Byte-Pair Encoding (BPE) that has become the backbone of modern language models.
The Core Challenge: From Language to Vectors
Machine learning models work with vectors, not text. They need numerical inputs to perform their mathematical operations. So how do we bridge this gap between the rich, complex world of human language and the numerical world of ML models?
The answer lies in a two-step process:
- Convert language to a sequence of integers
- Convert integers to vectors using embeddings
For the second step, we typically use lookup tables (embeddings) that map each integer to a high-dimensional vector. This is often done through one-hot encoding, where we map numbers from 1 to 100 to a 100-dimensional vector with a 1 in the $\text{k}^{th}$ position and 0’s everywhere else. The key insight is that one-hot encodings let you think about each integer independently, which is useful when integers represent distinct categories or tokens.
But the real challenge lies in the first step: how do we convert arbitrary text into a bounded sequence of integers?
Idea 1: Use a Dictionary
The most straightforward approach would be to create a vocabulary from a dictionary. Each word gets assigned an integer, and we’re done!
Problem: This approach fails miserably with real-world text. It can’t handle:
- URLs and special characters
- Punctuation variations
- Misspellings and typos
- New words not in the dictionary
Idea 2: Character-Level Tokenization
What if we just use the 256 ASCII characters as our vocabulary? This gives us:
- Fixed vocabulary size
- Ability to handle arbitrary text
- Complete coverage of any input
Problem: This loses the structure of language. Some sequences of characters are far more meaningful than others. “Language” should be treated as a single meaningful unit, while “hjsksdfiu” shouldn’t be. Character-level tokenization is inefficient and doesn’t capture the hierarchical nature of language.
The Solution: Byte-Pair Encoding
This is where BPE comes to the rescue. It’s an elegant algorithm that starts with characters and gradually builds up meaningful subwords and words by finding the most frequent pairs and merging them.
How Byte-Pair Encoding Works
BPE begins with the 256 ASCII characters as the initial vocabulary. Then it iteratively finds the most common pair of adjacent tokens and merges them into a new token. This process continues for a predetermined number of iterations (typically around 50,000 for large-scale models).
Let’s implement a simple BPE algorithm step by step:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from collections import defaultdict
class SimpleBPE:
def __init__(self):
self.merges = []
self.vocabs = set()
# step 1:
def get_word_tokens(self, text):
...
return word_tokens
# step 2:
def get_pairs(self, word_tokens)
...
return pairs
# step 3:
def merge_pairs(self, word_tokens, pairs_to_merge):
...
return word_tokens
# step 4:
def train(self, text, num_merges=10):
...
# merging pairs are updated
# vocabulary is built
return word_tokens
# encode for new text with learned
def encode(self, text):
...
return tokens
Step 1: Start with Characters and End-of-Word Markers
The first step is to break every word down into individual characters, but with a crucial addition: a special end-of-word marker </w>.
Why do we need the end-of-word marker?
Without the marker, BPE can’t distinguish between:
- The “s” at the end of “cats” (which indicates plural)
- The “s” in the middle of “master” (which is just part of the word)
This distinction is crucial for learning meaningful morphological patterns.
1
2
3
4
5
6
7
8
9
class SimpleBPE:
...
def get_word_tokens(self, text):
word_tokens = []
words = text.lower().split()
for word in words:
tokens = list(word) + ['</w>']
word_tokens.append(tokens)
return word_tokens
Let’s see this in action with a sample text:
1
2
3
4
5
6
text = """
the quick brown fox jumps over the lazy dog
the dog was very lazy and the fox was quick
brown dogs and quick foxes are common
the lazy brown dog sleeps while the quick fox runs
"""
The function get_word_tokens returns:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
[['t', 'h', 'e', '</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['b', 'r', 'o', 'w', 'n', '</w>'],
['f', 'o', 'x', '</w>'],
['j', 'u', 'm', 'p', 's', '</w>'],
['o', 'v', 'e', 'r', '</w>'],
['t', 'h', 'e', '</w>'],
['l', 'a', 'z', 'y', '</w>'],
['d', 'o', 'g', '</w>'],
['t', 'h', 'e', '</w>'],
['d', 'o', 'g', '</w>'],
['w', 'a', 's', '</w>'],
['v', 'e', 'r', 'y', '</w>'],
['l', 'a', 'z', 'y', '</w>'],
['a', 'n', 'd', '</w>'],
['t', 'h', 'e', '</w>'],
['f', 'o', 'x', '</w>'],
['w', 'a', 's', '</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['b', 'r', 'o', 'w', 'n', '</w>'],
['d', 'o', 'g', 's', '</w>'],
['a', 'n', 'd', '</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['f', 'o', 'x', 'e', 's', '</w>'],
['a', 'r', 'e', '</w>'],
['c', 'o', 'm', 'm', 'o', 'n', '</w>'],
['t', 'h', 'e', '</w>'],
['l', 'a', 'z', 'y', '</w>'],
['b', 'r', 'o', 'w', 'n', '</w>'],
['d', 'o', 'g', '</w>'],
['s', 'l', 'e', 'e', 'p', 's', '</w>'],
['w', 'h', 'i', 'l', 'e', '</w>'],
['t', 'h', 'e', '</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['f', 'o', 'x', '</w>'],
['r', 'u', 'n', 's', '</w>']]
Step 2: Find the Most Frequent Pair
Next, we scan through all the tokenized words and count how frequently each pair of adjacent tokens appears.
1
2
3
4
5
6
7
8
9
class SimpleBPE:
...
def get_pairs(self, word_tokens):
pairs = defaultdict(int)
for word in word_tokens:
for i in range(len(word)-1):
pair = (pair[i], pair[i+1])
pairs[pair] += 1
return pairs
For our extracted word_tokens, the function get_pairs returns:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
{('t', 'h'): 6,
('h', 'e'): 6,
('e', '</w>'): 8,
('q', 'u'): 4,
('u', 'i'): 4,
('i', 'c'): 4,
('c', 'k'): 4,
('k', '</w>'): 4,
('b', 'r'): 3,
('r', 'o'): 3,
('o', 'w'): 3,
('w', 'n'): 3,
('n', '</w>'): 4,
('f', 'o'): 4,
('o', 'x'): 4,
('x', '</w>'): 3,
('j', 'u'): 1,
('u', 'm'): 1,
('m', 'p'): 1,
('p', 's'): 2,
('s', '</w>'): 7,
('o', 'v'): 1,
('v', 'e'): 2,
('e', 'r'): 2,
('r', '</w>'): 1,
('l', 'a'): 3,
('a', 'z'): 3,
('z', 'y'): 3,
('y', '</w>'): 4,
('d', 'o'): 4,
('o', 'g'): 4,
('g', '</w>'): 3,
('w', 'a'): 2,
('a', 's'): 2,
('r', 'y'): 1,
('a', 'n'): 2,
('n', 'd'): 2,
('d', '</w>'): 2,
('g', 's'): 1,
('x', 'e'): 1,
('e', 's'): 1,
('a', 'r'): 1,
('r', 'e'): 1,
('c', 'o'): 1,
('o', 'm'): 1,
('m', 'm'): 1,
('m', 'o'): 1,
('o', 'n'): 1,
('s', 'l'): 1,
('l', 'e'): 2,
('e', 'e'): 1,
('e', 'p'): 1,
('w', 'h'): 1,
('h', 'i'): 1,
('i', 'l'): 1,
('r', 'u'): 1,
('u', 'n'): 1,
('n', 's'): 1}
Step 3: Merge the Most Frequent Pair
Now we replace all instances of the most frequent pair with a new single token.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class SimpleBPE:
....
def merge_pairs(word_tokens, pairs_to_merge):
new_word_tokens = []
for word in word_tokens:
new_word = []
i = 0
while i < len(word) - 1:
if i < len(word) - 1 and word[i] == pairs_to_merge[0] and word[i+1] == pairs_to_merge[1]:
merged_token = word[i] + word[i+1]
new_word.append(merged_token)
i += 2
else:
new_word.append(word[i])
i += 1
new_word_tokens.append(new_word)
return new_word_tokens
The most frequent pair is ('e', '</w>') with a count of 8. The function merge_pairs would then return:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
[['t', 'h', 'e</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['b', 'r', 'o', 'w', 'n', '</w>'],
['f', 'o', 'x', '</w>'],
['j', 'u', 'm', 'p', 's', '</w>'],
['o', 'v', 'e', 'r', '</w>'],
['t', 'h', 'e</w>'],
['l', 'a', 'z', 'y', '</w>'],
['d', 'o', 'g', '</w>'],
['t', 'h', 'e</w>'],
['d', 'o', 'g', '</w>'],
['w', 'a', 's', '</w>'],
['v', 'e', 'r', 'y', '</w>'],
['l', 'a', 'z', 'y', '</w>'],
['a', 'n', 'd', '</w>'],
['t', 'h', 'e</w>'],
['f', 'o', 'x', '</w>'],
['w', 'a', 's', '</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['b', 'r', 'o', 'w', 'n', '</w>'],
['d', 'o', 'g', 's', '</w>'],
['a', 'n', 'd', '</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['f', 'o', 'x', 'e', 's', '</w>'],
['a', 'r', 'e</w>'],
['c', 'o', 'm', 'm', 'o', 'n', '</w>'],
['t', 'h', 'e</w>'],
['l', 'a', 'z', 'y', '</w>'],
['b', 'r', 'o', 'w', 'n', '</w>'],
['d', 'o', 'g', '</w>'],
['s', 'l', 'e', 'e', 'p', 's', '</w>'],
['w', 'h', 'i', 'l', 'e</w>'],
['t', 'h', 'e</w>'],
['q', 'u', 'i', 'c', 'k', '</w>'],
['f', 'o', 'x', '</w>'],
['r', 'u', 'n', 's', '</w>']]
Step 4: Repeat the Process
We continue this process for a predetermined number of iterations, each time finding the most frequent pair and merging it.
1
2
3
4
5
6
7
8
9
10
11
12
13
class SimpleBPE:
...
def train(self, text, num_merges = 10):
word_tokens = self.get_word_tokens(text)
for _ in range(num_merges):
pairs = self.get_pairs(word_tokens)
if not pairs:
break
most_frequent_pairs = max(pairs, key=pairs.get)
frequency = pairs[most_frequent_pairs]
word_tokens = merge_pairs(word_tokens, most_frequent_pairs)
merges.append(most_frequent_pairs)
After 15 merges, the most frequent pairs list would look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[('e', '</w>'),
('s', '</w>'),
('t', 'h'),
('th', 'e</w>'),
('q', 'u'),
('qu', 'i'),
('qui', 'c'),
('quic', 'k'),
('quick', '</w>'),
('n', '</w>'),
('f', 'o'),
('fo', 'x'),
('y', '</w>'),
('d', 'o'),
('do', 'g')]
Step 5: Build the Final Vocabulary
Finally, we collect all the tokens that appear in our final tokenization to build our vocabulary.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class SimpleBPE:
...
def train(self, text, num_merges = 10):
word_tokens = self.get_word_tokens(text)
for _ in range(num_merges):
pairs = self.get_pairs(word_tokens)
if not pairs:
break
most_frequent_pairs = max(pairs, key=pairs.get)
frequency = pairs[most_frequent_pairs]
word_tokens = merge_pairs(word_tokens, most_frequent_pairs)
merges.append(most_frequent_pairs)
# build vocabulary
for word in word_tokens:
self.vocabs.update(word)
return word_tokens
After 15 merges, the updated word_tokens would look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
[['the</w>'],
['quick</w>'],
['b', 'r', 'o', 'w', 'n</w>'],
['fox', '</w>'],
['j', 'u', 'm', 'p', 's</w>'],
['o', 'v', 'e', 'r', '</w>'],
['the</w>'],
['l', 'a', 'z', 'y</w>'],
['dog', '</w>'],
['the</w>'],
['dog', '</w>'],
['w', 'a', 's</w>'],
['v', 'e', 'r', 'y</w>'],
['l', 'a', 'z', 'y</w>'],
['a', 'n', 'd', '</w>'],
['the</w>'],
['fox', '</w>'],
['w', 'a', 's</w>'],
['quick</w>'],
['b', 'r', 'o', 'w', 'n</w>'],
['dog', 's</w>'],
['a', 'n', 'd', '</w>'],
['quick</w>'],
['fox', 'e', 's</w>'],
['a', 'r', 'e</w>'],
['c', 'o', 'm', 'm', 'o', 'n</w>'],
['the</w>'],
['l', 'a', 'z', 'y</w>'],
['b', 'r', 'o', 'w', 'n</w>'],
['dog', '</w>'],
['s', 'l', 'e', 'e', 'p', 's</w>'],
['w', 'h', 'i', 'l', 'e</w>'],
['the</w>'],
['quick</w>'],
['fox', '</w>'],
['r', 'u', 'n', 's</w>']]
The vocabulary built contains:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
{'</w>',
'a',
'b',
'c',
'd',
'dog',
'e',
'e</w>',
'fox',
'h',
'i',
'j',
'l',
'm',
'n',
'n</w>',
'o',
'p',
'quick</w>',
'r',
's',
's</w>',
'the</w>',
'u',
'v',
'w',
'y</w>',
'z'}
Encoding New Text
Once we have our trained BPE model, we can use it to encode new text by applying the same sequence of merges we learned during training.
1
2
3
4
5
6
7
8
9
10
11
class SimpleBPE:
...
def encode(self, text):
word_tokens = self.get_word_tokens(text)
pairs = self.merges
for pair in pairs:
word_tokens = self.merge_pairs(word_tokens, pair)
tokens = []
for word in word_tokens:
tokens.extend(word)
return tokens
If you encode the new text “the quick lazy fox”, the tokens will be:
1
['the</w>', 'quick</w>', 'l', 'a', 'z', 'y</w>', 'fox', '</w>']
Why BPE Works So Well
The beauty of BPE lies in its data-driven approach to discovering meaningful language patterns:
Automatic Discovery: It automatically finds common prefixes, suffixes, and complete words without any linguistic knowledge.
Balanced Vocabulary: It creates an efficient vocabulary that balances between having too many rare symbols and too few common ones.
Morphological Awareness: By using end-of-word markers, it learns to distinguish between morphological patterns (like plurals, verb endings) and random character sequences.
Scalability: The algorithm scales well and can handle large corpora to build comprehensive vocabularies.
Flexibility: It can handle out-of-vocabulary words by breaking them down into known subword units.
Real-World Impact
BPE has becomes the foundation for tokenization in most modern language models, including GPT, BERT, and many others. While production systems use more sophisticated variations (like SentencePiece or different special tokens), the core principle remains the same: start simple and let the data guide you to discover meaningful patterns.
The tokens that include </w> markers aren’t a bug—they’re a feature that helps language models understand the structure and boundaries of language, leading to better performance on downstream tasks.
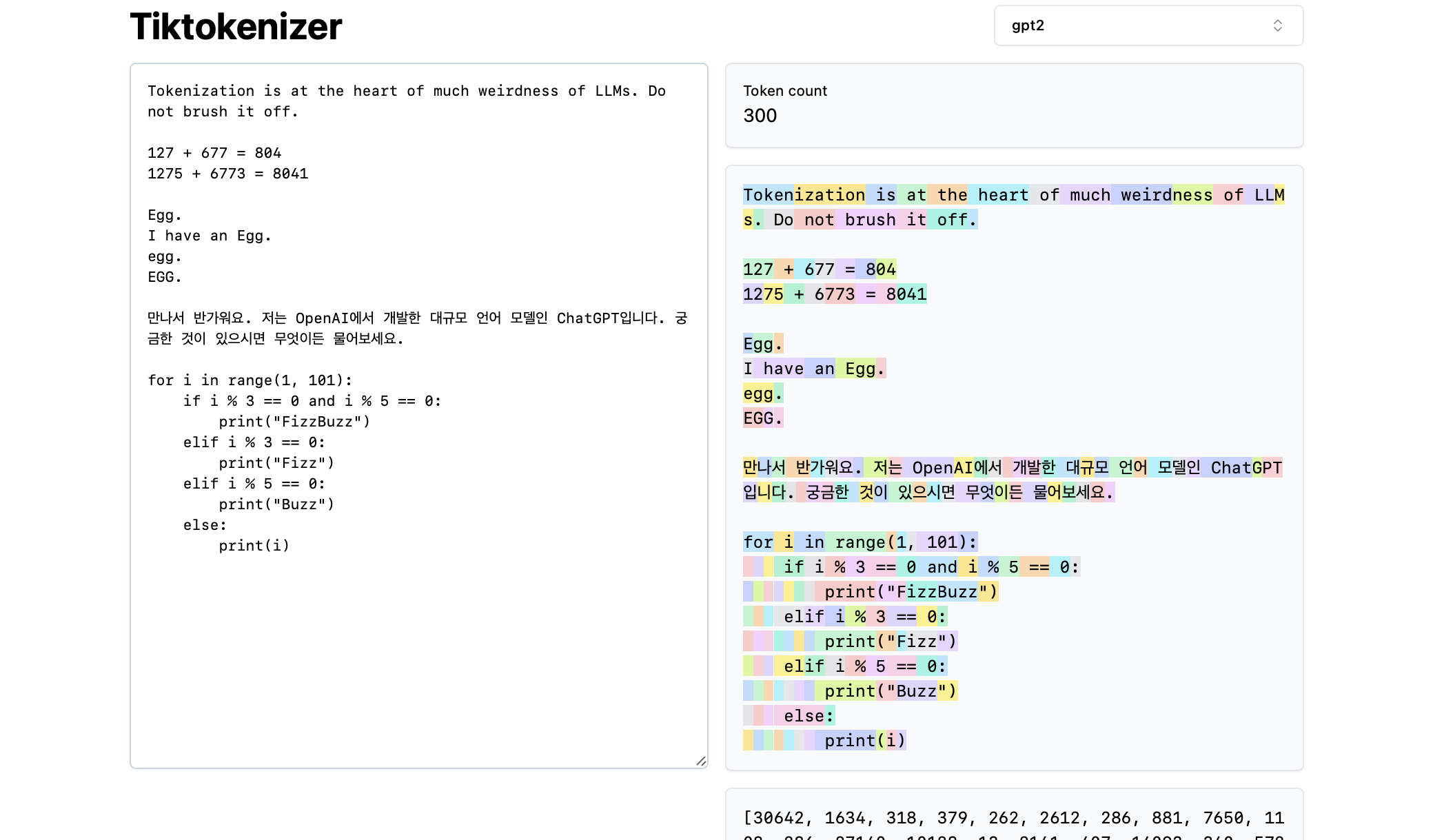
Let’s play around with GPT-2 style tokenizer
GPT-2 uses BPE, which can produce both whole words and subwords.
Loading GPT-2 (the Easy Way)
Here, we’re loading a lightweight, inspectable version of GPT-2 (“gpt2-small”) using the EasyTransformer library.
1
2
3
4
5
# %pip install git+https://github.com/redwoodresearch/Easy-Transformer.git
from easy_transformer import EasyTransformer
reference_gpt2 = EasyTransformer.from_pretrained("gpt2-small", fold_ln=False, center_unembed=False, center_writing_weights=False)
Let’s take a look at the tokenizer’s vocabulary by sorting it by token ID:
1
2
3
4
5
6
7
sorted_vocab = sorted(list(reference_gpt2.tokenizer.vocab.items()), key=lambda n:n[1])
print(sorted_vocab[:20])
print()
print(sorted_vocab[250:270])
print()
print(sorted_vocab[990:1010])
print()
1
2
3
4
5
6
7
8
9
10
11
12
First 20 Tokens: These are mostly printable ASCII characters — basic building blocks.
[('!', 0), ('"', 1), ('#', 2), ('$', 3), ('%', 4), ('&', 5), ("'", 6), ('(', 7), (')', 8), ('*', 9), ('+', 10), (',', 11), ('-', 12), ('.', 13), ('/', 14), ('0', 15), ('1', 16), ('2', 17), ('3', 18), ('4', 19)]
Tokens Around ID 250: Now we start seeing interesting patterns — some accented characters, multi-byte sequences, and tokens prefixed with `Ġ` which denotes a space.
[('ľ', 250), ('Ŀ', 251), ('ŀ', 252), ('Ł', 253), ('ł', 254), ('Ń', 255), ('Ġt', 256), ('Ġa', 257), ('he', 258), ('in', 259), ('re', 260), ('on', 261), ('Ġthe', 262), ('er', 263), ('Ġs', 264), ('at', 265), ('Ġw', 266), ('Ġo', 267), ('en', 268), ('Ġc', 269)]
Tokens Around ID 1000: Many of these are common word prefixes or subwords. GPT-2 tokenizes based on frequency, so fragments like `Ġprodu` and `ution` allow flexible reconstruction of words like _production_ or _revolution_.
[('Ġprodu', 990), ('Ġstill', 991), ('led', 992), ('ah', 993), ('Ġhere', 994), ('Ġworld', 995), ('Ġthough', 996), ('Ġnum', 997), ('arch', 998), ('imes', 999), ('ale', 1000), ('ĠSe', 1001), ('ĠIf', 1002), ('//', 1003), ('ĠLe', 1004), ('Ġret', 1005), ('Ġref', 1006), ('Ġtrans', 1007), ('ner', 1008), ('ution', 1009)]
Last 20 tokens: These are rare or special-case tokens, including names, obscure words, and GPT-2’s end-of-text marker <|endoftext|>.
1
sorted_vocab[-20:]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[('Revolution', 50237),
('Ġsnipers', 50238),
('Ġreverted', 50239),
('Ġconglomerate', 50240),
('Terry', 50241),
('794', 50242),
('Ġharsher', 50243),
('Ġdesolate', 50244),
('ĠHitman', 50245),
('Commission', 50246),
('Ġ(/', 50247),
('âĢ¦."', 50248),
('Compar', 50249),
('Ġamplification', 50250),
('ominated', 50251),
('Ġregress', 50252),
('ĠCollider', 50253),
('Ġinformants', 50254),
('Ġgazed', 50255),
('<|endoftext|>', 50256)]
How are the sentence tokenized?
1
2
3
print(reference_gpt2.to_tokens("Whether a word begins with a capital or space matters!"))
print()
print(reference_gpt2.to_tokens("Whether a word begins with a capital or space matters!", prepend_bos=False))
1
2
3
4
5
tensor([[50256, 15354, 257, 1573, 6140, 351, 257, 3144, 498, 393,
2272, 6067, 0]])
tensor([[15354, 257, 1573, 6140, 351, 257, 3139, 393, 2272, 6067,
0]])
Let’s look at one word — Ralph — in a few forms:
1
2
3
4
print(reference_gpt2.to_str_tokens("Ralph"))
print(reference_gpt2.to_str_tokens(" Ralph"))
print(reference_gpt2.to_str_tokens(" ralph"))
print(reference_gpt2.to_str_tokens("ralph"))
1
2
3
4
['<|endoftext|>', 'R', 'alph']
['<|endoftext|>', ' Ralph']
['<|endoftext|>', ' r', 'alph']
['<|endoftext|>', 'ral', 'ph']
- The lowercase
'ralph'gets split into subwords like'ral'and'ph'. - Even just adding a space (
' Ralph') causes it to become a distinct token (' Ralph'), reflecting how the tokenizer tracks word boundaries.
How are numbers tokenized?
1
reference_gpt2.to_str_tokens("56873+3184623=123456789-1000000000")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
['<|endoftext|>',
'568',
'73',
'+',
'318',
'46',
'23',
'=',
'123',
'45',
'67',
'89',
'-',
'1',
'000000',
'000']
GPT-2 breaks numbers into chunks that appear frequently in training data. For instance:
- Long sequences of
0s are grouped ('000000','000'). - Common numerical patterns (
'123','45','89') form individual tokens. - Punctuation (
+, =,-) is tokenized separately.
Takeaways
- We construct a vocabulary dictionary containing sub-word token units
- We transform text into integer sequences through tokenization with minimal information loss
- We map these integers to dense vectors using embedding lookup tables
- Note: Transformers process token sequences as their primary input, with vectors serving as learned representations