Point Cloud Fusion with Diffusion Models - An Integrated Pipeline for High-Quality Surround View Rendering
Poster

Abstract
Automotive surround view systems are critical for driver assistance during low-speed maneuvering, yet conventional rendering pipelines suffer from significant visual artifacts including the Manhattan effect (ghosting), missing pixels, and non-photorealistic outputs that compromise driver perception and safety. This paper introduces a novel image synthesis pipeline that addresses these challenges through an integrated approach combining 3D point cloud reconstruction with denoising diffusion models. The method fuses RGBD images from multiple surround-view cameras into a unified point cloud representation, renders novel viewpoints through geometric re-projection, and employs a conditional diffusion model to refine the output and suppress rendering artifacts. By formulating novel view synthesis as an image-to-image translation problem, the pipeline leverages the generative capabilities of diffusion models to produce photorealistic outputs with significantly improved perceptual quality. Extensive qualitative evaluations across diverse driving scenarios—including parallel parking, perpendicular parking, and various weather conditions—demonstrate the effectiveness of this approach for production-level automotive applications, though challenges remain in handling large occlusions and unseen objects.
Core Idea
The Problem: Limitations of Traditional Surround View Systems
Modern vehicles rely on 360-degree surround view systems that combine multiple fish-eye cameras to provide comprehensive environmental awareness during parking and low-speed maneuvers. While these systems have evolved from simple rear-view assistance to sophisticated 3D bowl-shaped projection models, they continue to suffer from three critical rendering challenges:
- Manhattan Effect: Unwanted duplication or ghosting artifacts where vertical structures appear distorted
- Blacked-out Pixels: Missing information in regions where camera coverage is insufficient or geometric projection fails
- Non-photorealistic Rendering: Limited visual fidelity that reduces driver confidence and situational awareness
These artifacts arise from the fundamental limitations of geometric projection methods when dealing with complex 3D scenes, occlusions, and the transition between different camera viewpoints.
The Solution: Point Cloud Fusion with Diffusion-Based Refinement
The proposed pipeline introduces a two-stage approach that bridges classical 3D reconstruction with modern generative AI:
Stage 1: Point Cloud Generation and Re-projection The system begins by collecting RGBD (RGB + Depth) images from four surround-view cameras with overlapping fields of view. Using standard pinhole camera parameters, these images are fused into a unified 3D point cloud representation P ∈ ℝ^(N×6), where each of N points contains both spatial coordinates (x, y, z) and color information (r, g, b). Critically, the ego vehicle is excluded from this point cloud but maintained as prior knowledge to ensure perfect rendering from any viewpoint.
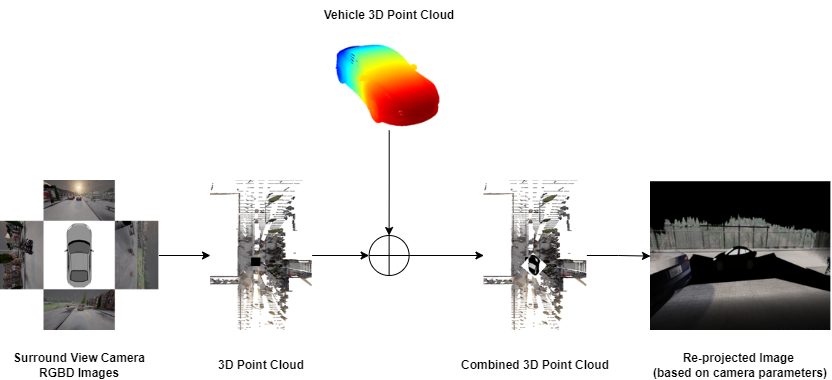
This point cloud serves as a geometric proxy for the scene and can be re-projected to arbitrary novel viewpoints using camera transformation matrices. However, this geometric rendering inevitably produces artifacts—particularly missing pixels in occluded regions and areas with insufficient point density.
Stage 2: Diffusion-Based Image Refinement Rather than accepting these artifacts, the pipeline treats the re-projected image as a conditional input to a denoising diffusion model, specifically adapted from the Palette architecture for image-to-image translation. The key innovation lies in formulating artifact removal as a conditional inpainting problem:
- The diffusion model is trained on paired data: re-projected images with artifacts (input) and ground-truth camera images (target)
- Masks are generated to identify missing pixels and artifact regions
- The model learns to fill these regions while preserving the valid geometric structure from the point cloud
- During inference, the model performs iterative refinement over 1000 denoising steps, progressively transforming Gaussian noise into realistic image content conditioned on the masked re-projection
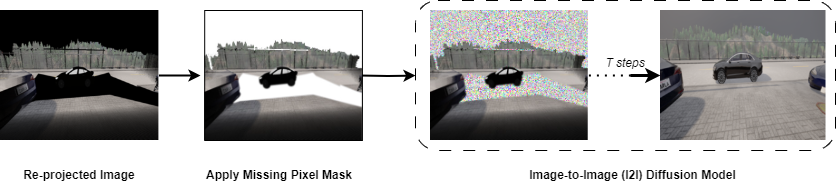
This approach differs fundamentally from existing methods by combining the geometric consistency of point cloud rendering with the generative power of diffusion models, avoiding the expensive per-scene optimization required by NeRF-based approaches while handling severe occlusions more effectively than traditional inpainting methods.
Experimental Results
Datasets and Evaluation Setup
The research employed two training datasets and three comprehensive test sets, all generated using the CARLA simulator:
Training Data:
- General Dataset: 82,641 images from typical driving scenarios in CARLA Town 1
- Multi-Town Dataset: 8,441 images emphasizing parallel parking across Towns 1-5 with 8 diverse weather conditions
Test Sets:
- Test Set 1: 2,016 images of parallel parking across 16 weather conditions (Town 1)
- Test Set 2: 1,056 images of parallel parking across 5 towns with additional objects (pedestrians, bicycles, safety cones)
- Test Set 3: 1,056 images of perpendicular parking scenarios (Town 1)
All datasets utilized 4 surround-view cameras and 29 third-person viewpoint cameras with 120° field of view, generating paired RGBD images for training and evaluation.
Quantitative Performance Metrics
The pipeline was evaluated using five standard image quality metrics across all test sets:
| Test Dataset | FID (↓) | IS (↑) | LPIPS (↓) | PSNR (↑) | SSIM (↑) |
|---|---|---|---|---|---|
| Test Set 1 (Weather Variation) | 36.93 | 3.71 | 0.10 | 24.08 | 0.80 |
| Test Set 2 (Multi-Town + Objects) | 24.73 | 3.24 | 0.05 | 27.05 | 0.85 |
| Test Set 3 (Perpendicular Parking) | 33.59 | 3.34 | 0.11 | 24.81 | 0.81 |
Key Findings:
- Best Overall Performance: Test Set 2 achieved the lowest FID score (24.73) and highest PSNR (27.05) and SSIM (0.85), likely due to similarity with training data distribution
- Consistent Quality: All test sets maintained SSIM scores above 0.80, indicating strong structural preservation
- Perceptual Similarity: LPIPS scores remained low (0.05-0.11), demonstrating perceptually realistic outputs
Qualitative Analysis and Model Behavior
Selected Visual Comparisons Across Three Test Sets

Strengths:
- Ego Vehicle Reconstruction: Perfect rendering of the vehicle itself across all viewpoints due to 3D point cloud prior knowledge
- Small Region Inpainting: Excellent performance filling small missing regions with appropriate textures
- Familiar Scene Handling: Strong results on scenarios similar to training data distribution
- Structural Consistency: Maintained geometric coherence from point cloud representation
Limitations Identified:
- Large Occlusions: Struggled with extensive missing regions containing multiple distinct textures
- Novel Objects: Partial reconstruction of objects not seen during training (e.g., bicycles in Test Set 2)
- Weather Consistency: Occasional inconsistencies when inpainting large sky regions across different weather conditions
- Texture Hallucination: Sometimes filled parking spaces with inappropriate textures from nearby pixels
Practical Implications
The results demonstrate that the proposed pipeline achieves significant improvements in visual quality over raw point cloud renderings, particularly for scenarios within the training distribution. The approach shows promise for production automotive applications where:
- Driver confidence is enhanced through photorealistic visualization
- Geometric accuracy is maintained through point cloud representation
- Computational feasibility exists for near-real-time processing (though optimization needed)
However, the identified limitations around novel objects and large occlusions indicate that deployment in safety-critical systems would require additional safeguards, uncertainty visualization, and integration with other sensor modalities.
Citation
If you use this work, please cite it as follows:
1
2
3
4
5
6
7
8
@inproceedings{rajendran2025point,
author = {Vinod Rajendran},
title = {Point Cloud Fusion with Diffusion Models: An Integrated Pipeline for High-Quality Surround View Rendering},
booktitle = {Advances in Visual Computing - 20th International Symposium, {ISVC} 2025, Las Vegas, NV, USA, November 17-19, 2025, Proceedings, Part{II}},
series = {Lecture Notes in Computer Science},
year = {2025},
publisher = {Springer}
}