Notes
27.02.2025
- A guide to JAX for PyTorch developers - Google Cloud Blog
- deeptutor.knowhiz.us/upload - Paper reading assistant with deeper understanding.
- phind - A visual search engine
- geekan/MetaGPT: 🌟 The Multi-Agent Framework: First AI Software Company, Towards Natural Language Programming - MetaGPT helps you transform a single-line requirement into detailed user stories, competitive analyses, requirements, data structures, APIs, and documentation. It assigns roles like product manager, architect, project manager, and engineer to AI agents, simulating a software company’s workflow.
- NirDiamant/GenAI_Agents: This repository provides tutorials and implementations for various Generative AI Agent techniques, from basic to advanced. It serves as a comprehensive guide for building intelligent, interactive AI systems.- This repository helps you develop Generative AI agents, from simple conversational models to complex multi-agent systems. It provides step-by-step tutorials, ready-to-use implementations, and documentation. It covers agent architectures, practical applications, and real-world deployment.
07.03.2025
- ExplainGithub > Turn hours of code reading into minutes of understanding.
- MLOps python package - Kickstart your MLOps initiative with a flexible, robust, and productive Python package.
- TAID: A Novel Method for Efficient Knowledge Transfer from Large Language Models to Small Language Models
12.03.2025
15 Mind-Blowing AI Statistics Everyone Must Know About Now
- 34 million AI-Generated Images Created Daily
- 71% Of Social Media Images Now AI-Generated
- Deepfake Fraud Attempts Surge To 6.5% Worldwide
- Tech Giants Investing $320 Billion In AI Development For 2025
- Global AI Services Market To Reach $243 Billion This Year
- 97% Of Leaders Investing In AI Report Positive Return On Investment
- 25% Of Enterprises Will Deploy AI Agents This Year
- Healthcare AI Market Valued At $38.7 Billion, Doubling Since 2023
- Adoption Gap: 81% Of Workers Still Not Using AI Tools
- Trust Divide: AI Acceptance High In India (77%) and China (72%), Low In America ((32%)
- AI Influencer Economy Approaching $7 Billion Valuation
- Data Centers To Consume 5% Of U.S. Power, Doubling By 2030
- 30% Of New Smartphones To Feature On-Device GenAI
- 50% Of Companies That Use AI Incorporate Open-Source Solutions
- Nearly Half Of Tech Leaders (49%) Say AI Is Now Fully Integrated Into Business Strategy
- Open R1 for Students - Hugging Face NLP Course
- Reinforcement Learning Course
13.03.2025
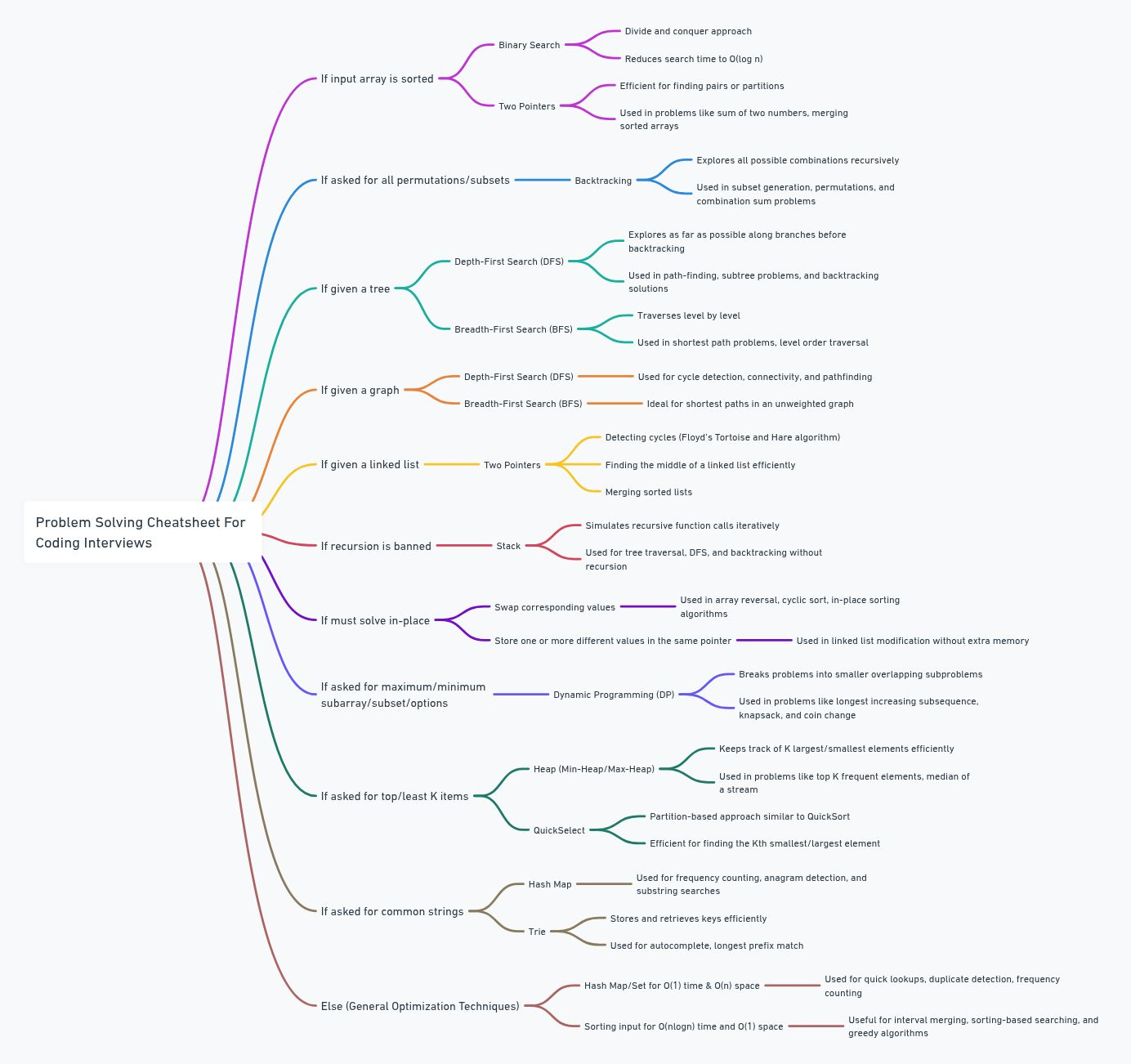
I’ve gathered valuable insights that have helped me succeed in solving complex problems during coding interviews. Here’s what I’ve learned:
1. If the Input Array is Sorted
When you are given a sorted array, there are two go-to techniques that will make your job easier:
Binary Search
When to use it: Binary search is the optimal solution for searching for an element or solving problems related to finding a position in a sorted array.
How it works: Binary search works by repeatedly dividing the search interval in half. It starts by comparing the target value to the element in the middle. If they are not equal, it eliminates half of the search space.
Key advantage: It operates in O(log n) time complexity, which is much faster than a linear scan (O(n)).
Two Pointers
When to use it: If the problem asks to find pairs or elements satisfying certain conditions (e.g., sum equals to a target), two pointers is your best choice for a sorted array.
How it works: You initiate two pointers—one starting from the beginning of the array and the other from the end—and move them toward each other based on the condition you’re trying to satisfy.
Key advantage: The time complexity of this approach is O(n), and it’s very efficient for problems involving pairs or finding relationships between elements in sorted arrays.
2. If Asked for All Permutations/Subsets
When you’re asked to generate all permutations or subsets of a given set, the solution is usually based on backtracking.
Backtracking
When to use it: Backtracking is a powerful technique for solving problems where you have to explore all possibilities or combinations in a constrained space, like generating all permutations or subsets.
How it works: It involves exploring a potential solution space by building solutions incrementally, then abandoning a solution as soon as it is determined that it cannot be extended to a valid solution (this is known as “pruning”).
Key advantage: This method ensures you explore all possible combinations or permutations and works efficiently by reducing the search space through pruning.
3. If Given a Tree
When you’re working with a tree, whether it’s a binary tree or a general tree, there are two main strategies you should consider: Depth-First Search (DFS) and Breadth-First Search (BFS).
DFS
When to use it: DFS is most useful when you need to explore all possible paths (e.g., for finding paths, maximum depths, or solving tree traversal problems).
How it works: DFS explores as deep as possible down a branch before backtracking. It can be implemented recursively or using a stack.
Key advantage: It allows you to explore deeply nested nodes and works well for problems like pathfinding or tree traversal.
BFS
When to use it: BFS is ideal for level-order traversals, finding the shortest path in unweighted graphs, or problems where you need to explore nodes level by level.
How it works: BFS explores all neighbors of a node at the present depth level before moving on to nodes at the next depth level.
Key advantage: BFS guarantees that you find the shortest path in an unweighted graph and is useful for problems that require finding nodes at a certain level.
4. If Given a Graph
Graphs, whether directed, undirected, weighted, or unweighted, require two basic traversal techniques:
DFS
When to use it: Use DFS when you need to explore all possible paths in a graph (like finding connected components or cycles).
How it works: DFS can be implemented recursively or with an explicit stack. It explores deeper into the graph before backtracking.
Key advantage: It’s suitable for problems where deep exploration is needed, such as topological sorting or cycle detection.
BFS
When to use it: BFS is best when you’re looking for the shortest path, level-order traversal, or connected components.
How it works: BFS uses a queue to explore nodes level by level. It’s optimal for problems where the shortest path or level information is important.
Key advantage: BFS guarantees finding the shortest path in an unweighted graph and is ideal for problems like shortest-path algorithms.
5. If Given a Linked List
When given a linked list, two pointers is the most efficient technique.
Two Pointers
When to use it: Two pointers are used for problems such as detecting cycles in a linked list, finding the middle node, or reversing a linked list.
How it works: You initialize two pointers—slow and fast—where the slow pointer advances one step at a time, and the fast pointer advances two steps. This is helpful in problems involving the middle of a list or detecting loops.
Key advantage: This approach reduces time complexity and works effectively for problems requiring traversal with conditions on the steps.
6. If Recursion is Banned
Recursion can often be replaced by using a stack to simulate the recursion process.
Stack
When to use it: Use a stack to replace recursion for problems like depth-first search or when the recursive solution leads to a stack overflow due to deep recursion.
How it works: You maintain a stack of nodes or elements to process, and the algorithm processes them in a controlled, iterative manner.
Key advantage: It helps avoid the pitfalls of deep recursion and stack overflows while achieving the same result.
7. If You Must Solve In-Place
If the problem requires in-place operations, meaning you cannot use extra memory, you’ll rely on techniques like swapping values or storing multiple values in a single pointer.
Swap Corresponding Values
When to use it: This is useful for problems like reversing an array or swapping elements to solve problems like sorting.
How it works: You swap two values in-place without needing extra space.
Key advantage: It minimizes space complexity to O(1) while performing the operation efficiently.
Store Multiple Values in the Same Pointer
When to use it: This is typically used in problems like sorting or rearranging arrays where you can overwrite existing values as you progress.
How it works: You can overwrite or re-use memory locations to store intermediate values, which reduces memory usage.
Key advantage: It saves space and allows in-place modification of data structures.
8. If Asked for Maximum/Minimum Subarray/Subset/Options
Dynamic programming (DP) is your go-to approach for solving these problems efficiently.
Dynamic Programming
When to use it: DP is used for problems where the problem can be broken down into overlapping subproblems that can be solved optimally. It’s particularly useful for problems involving finding the maximum or minimum values in a sequence.
How it works: DP stores intermediate results to avoid redundant calculations. It can be implemented in both bottom-up (iterative) or top-down (recursive with memoization) approaches.
Key advantage: DP reduces time complexity from exponential to polynomial time in many cases, which makes it ideal for optimization problems.
9. If Asked for Top/Least K Items
For problems where you need to find the top K or least K elements, heaps or QuickSelect are the most efficient choices.
Heap
When to use it: Heaps are optimal for finding the k-th largest or smallest elements in an unsorted list.
How it works: A heap is a binary tree where each parent node is either larger or smaller than its child nodes. For top K or least K elements, a heap can be used to efficiently extract the largest or smallest elements.
Key advantage: Heaps provide an O(log n) time complexity for insertions and deletions, making them efficient for dynamic data.
QuickSelect
When to use it: QuickSelect is an efficient algorithm for finding the k-th largest or smallest element without fully sorting the array.
How it works: QuickSelect partitions the array and selects a subset of elements to recursively find the desired element in O(n) time on average.
Key advantage: QuickSelect is faster than sorting the entire array when you only need to find the k-th element.
10. If Asked for Common Strings
For problems that involve finding common strings or substrings, maps or tries are the best solutions.
Map
When to use it: A hash map can be used to track occurrences of strings, helping find common substrings or strings with certain properties.
How it works: You store the string’s frequency or occurrence in a map, and then easily retrieve values based on certain conditions.
Key advantage: Maps provide O(1) time complexity for lookups, making them highly efficient for these problems.
Trie
When to use it: A Trie is optimal for problems involving string matching or prefix-based queries.
How it works: A Trie is a tree-like data structure used for storing a dynamic set of strings, which is useful for finding common substrings or prefixes.
Key advantage: It allows for fast lookups and prefix-based searches in O(n) time complexity.
11. General Strategy
For problems not falling under any specific category, you can often use maps/sets for O(1) time complexity and O(n) space, or sorting for O(n log n) time complexity and O(1) space (depending on the problem).
Maps/Sets
When to use it: Maps and sets are used to store unique elements or key-value pairs. These structures give you efficient access to elements and allow you to check for membership in constant time.
Key advantage: They provide fast operations for insertion, deletion, and lookup, making them ideal for many problems involving unique elements or memberships.
Sorting
When to use it: Sorting is useful when you need to reorder data to apply algorithms like binary search or when working with problems like finding the kth smallest/largest element.
Key advantage: Sorting provides a way to convert a complex problem into a more manageable one, and many algorithms like binary search work well with sorted data.
14.03.2025
Can Zenoh revive Autonomous Vehicle Platooning?
First what is Autonomous Vehicle Platooning?
Rather than having a fleet of autonomous vehicles; you have ONE autonomous vehicle that acts as a “master”, and other “automated” vehicles that act as followers.
Imagine a convoy of trucks, where the first truck has all the sensors and intelligence, and communicates the instructions to its followers that then “break” or steer the vehicle.
This is platooning, a leader — and followers.
There are tons of theoretical advantages to using a platooning solution: reduced drag, shortest distance, no need to equip the entire fleet of truck with LiDARs, …
And it works like this:

The problem is, it never really worked.
It can work from a “prototype” perspective, but (to my knowledge) I don’t think the autonomous truck world ever adopted platooning as a solution.
One of the reasons is latency. You can’t risk sending a “break” instruction 1 second too late when a convoy of trucks drive at 90 km/h. It’s way too risky.
So what could you do?
You could try and reduce that communication latency.
Zenoh?
Sounds both Biblical & Star Wars like.
Whoever named it is a genius.
And what is it? It’s a better middleware for ROS.
ROS— a very brief definition would be: ROS is a middleware framework that helps algorithms communicate. We can have an object detector receiving images from multiple cameras and forwarding objects to a Trajectory Planner. It’s turning independent algorithms into a system.
To explain why Zenoh is a good idea, let me share a simple graph decomposing ROS into 4 main parts: Nodes, Tools, Robotics, and Ecosystem.
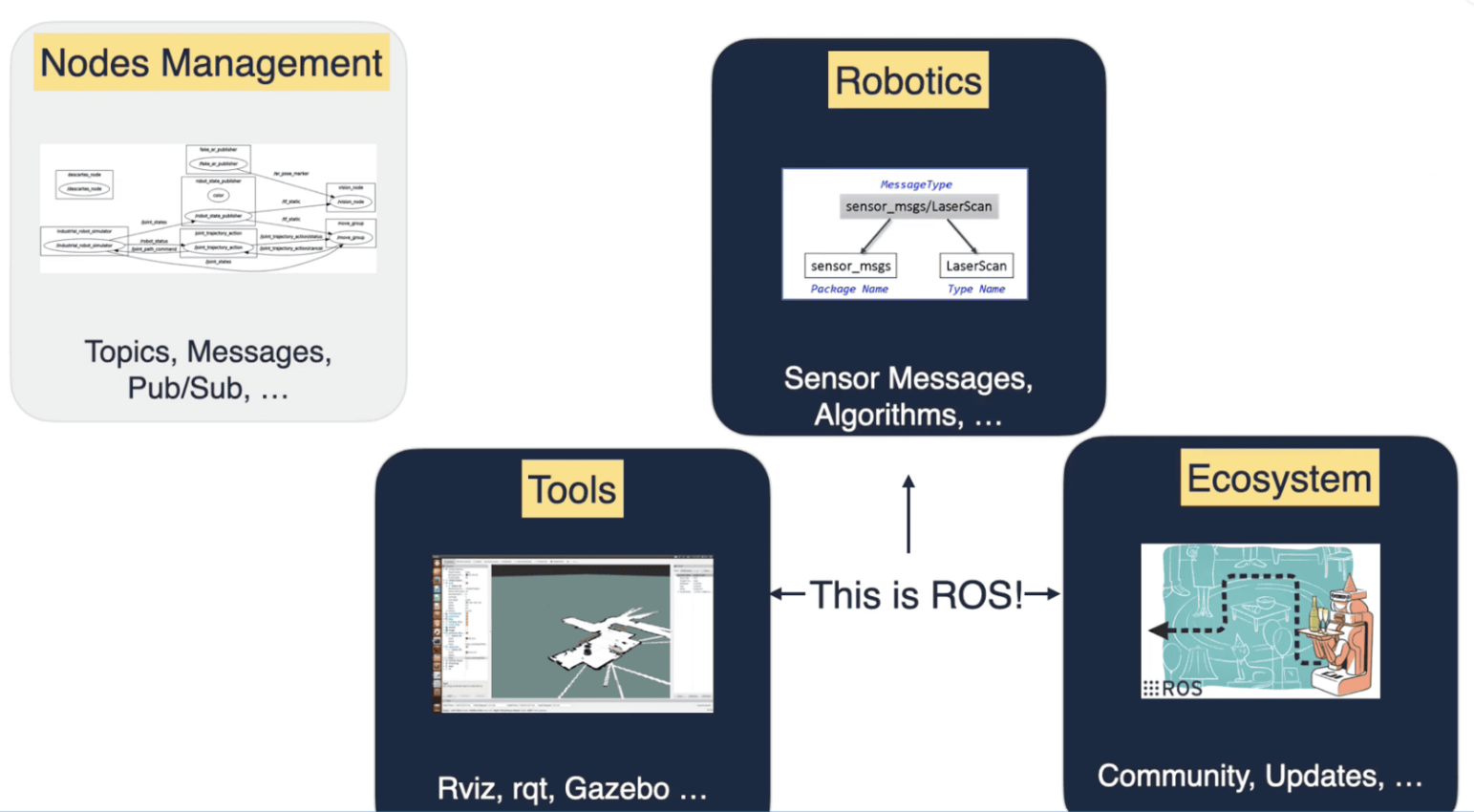
According to this:
- ROS = Nodes Management + Robotics Customization + Tools + Ecosystem
But the “nodes” part is NOT really ROS. It’s a standard protocol, like TCP for ROS1, and something called DDS for ROS2.
And what is Zenoh? A replacement for TCP and DDS in the “Nodes” part.
This means when you use it, nothing visibly changes: you still have Gazebo, messaging, etc… but under the hood, the protocol changes communication.
This is an under-the-hood modification.
But it’s very powerful, because while DDS (what ROS2 uses by default) was built for wired robotics, Zenoh is built for wireless robotics.
And when you replace the default ROS protocol, you turn a wired robot into a wireless robot.
And I think this is a solution to revive autonomous vehicle Platooning…
But you could also enable tons of other wireless applications, like Fleet Navigation, Drone Delivery, V2X, and many others…
17.03.2025
- MLOps Basics - The goal of the series is to understand the basics of MLOps like model building, monitoring, configurations, testing, packaging, deployment, cicd, etc.
21.03.2025
- Digital Hygiene - A list of things you can do to live a secure digital life.
- AI-blindspots - A list of coding blindspots in large language models (focused on the Sonnet family).
- Agent S2 -Agent S2: An Open, Modular, and Scalable Framework for Computer Use Agents
- rkinas/cuda-learning: This repository is a curated collection of resources, tutorials, and practical examples designed to guide you through the journey of mastering CUDA programming. Whether you’re just starting or looking to optimize and scale your GPU-accelerated applications.
24.03.2025
GenAI Agents It is a great resource for:
1/ learning
2/ building
3/ sharing AI Agentsranging from simple conversational bots to complex, multi-agent systems.
Key features:
🎓 Learn to build GenAI agents from beginner to advanced levels
🧠 Explore a wide range of agent architectures and applications
📚 Step-by-step tutorials and comprehensive documentation
🛠️ Practical, ready-to-use agent implementations
🌟 Regular updates with the latest advancements in GenAI
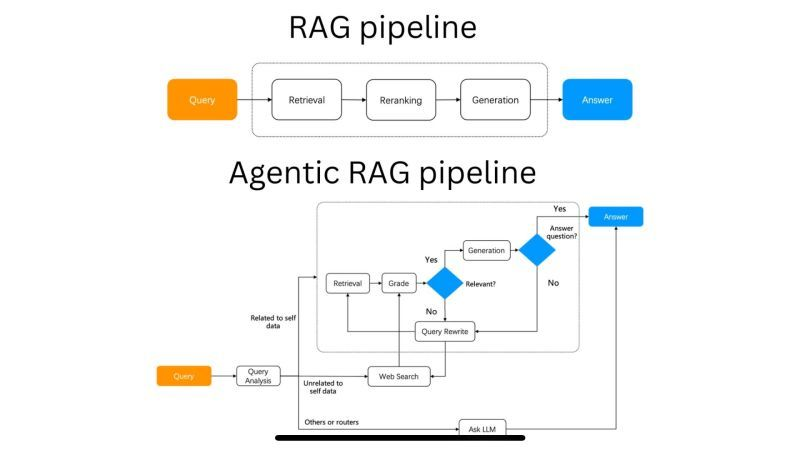
🤝 Share your own agent creations with the communityAgentic RAG 𝗡𝗮𝘁𝗶𝘃𝗲 𝗥𝗔𝗚
In Native RAG, the most common implementation nowadays, the user query is processed through a pipeline that includes retrieval, reranking, synthesis, and generation of a response.This process leverages retrieval and generation-based methods to provide accurate and contextually relevant answers.
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚
Agentic RAG is an advanced, agent-based approach to question answering over multiple documents in a coordinated manner. It involves comparing different documents, summarizing specific documents, or comparing various summaries.Agentic RAG is a flexible framework that supports complex tasks requiring planning, multi-step reasoning, tool use, and learning over time.
𝗞𝗲𝘆 𝗖𝗼𝗺𝗽𝗼𝗻𝗲𝗻𝘁𝘀 𝗮𝗻𝗱 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲
Document Agents: Each document is assigned a dedicated agent capable of answering questions and summarizing within its own document.
Meta-Agent: A top-level agent manages all the document agents, orchestrating their interactions and integrating their outputs to generate a coherent and comprehensive response.
𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀 𝗮𝗻𝗱 𝗕𝗲𝗻𝗲𝗳𝗶𝘁𝘀
Autonomy: Agents act independently to retrieve, process, and generate information.
Adaptability: The system can adjust strategies based on new data and changing contexts.
Proactivity: Agents can anticipate needs and take preemptive actions to achieve goals.
Applications
Agentic RAG is particularly useful in scenarios requiring thorough and nuanced information processing and decision-making.
A few days ago, I discussed how the future of AI lies in AI Agents. RAG is currently the most popular use case, and with an agentic architecture, you will supercharge RAG!
25.03.2025
- Last 2 week’s top AI/ML research papers:
- Transformers without Normalization
- Block Diffusion
- Compute Optimal Scaling of Skills
- DAPO: An OS LLM RL System at Scale
- Teaching LLMs How to Learn with Contextual Fine-Tuning
- GR00T N1 - Why the Brain Cannot Be a Digital Computer
- RWKV-7 “Goose” with Expressive Dynamic State Evolution
- Why Do Multi-Agent LLM Systems Fail?
- Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
- Light-R1
- Where do Large Vision-Language Models Look at when Answering Questions?
- Improving Planning of Agents for Long-Horizon Tasks
- UniCombine
- How much do LLMs learn from negative examples?
- Tokenize Image as a Set
- Search-R1
- Measuring AI Ability to Complete Long Tasks
- Does Your VLM Get Lost in the Long Video Sampling Dilemma?
- Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
- Personalize Anything for Free with Diffusion Transformer
- The KoLMogorov Test: Compression by Code Generation
- Optimizing ML Training with Metagradient Descent
- DeepMesh
- Thinking Machines
- A Review of DeepSeek Models
- A Survey on Efficient Reasoning
- Agentic Memory for LLM Agents
- GenAI-Showcase/notebooks/agents at main · mongodb-developer/GenAI-Showcase - Jupyter Notebooks demonstrating how to build AI agents using various frameworks and MongoDB Atlas as the vector store and memory provider.
- Which Agentic Framework should I use?
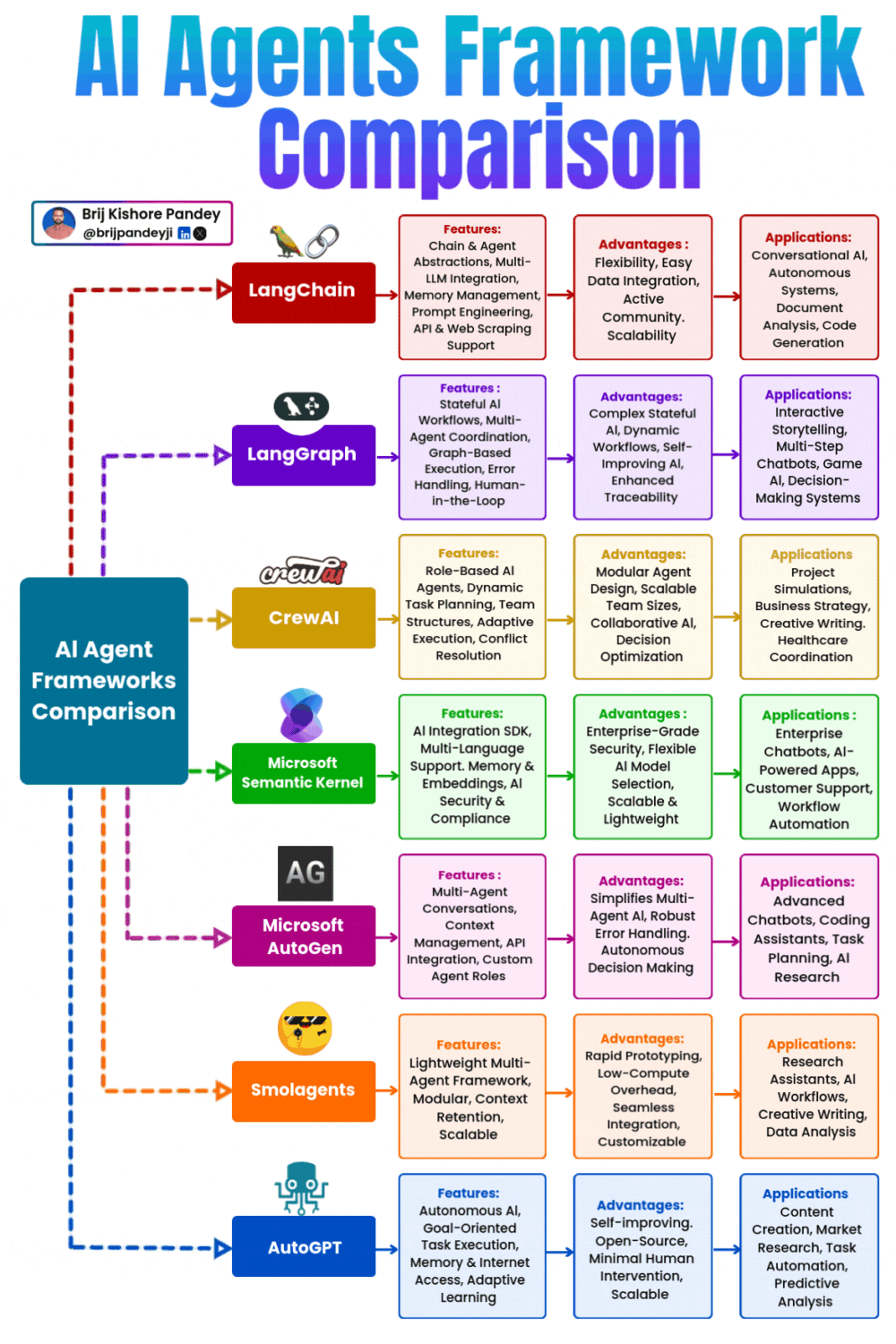
27.03.2025
- n8n-io/n8n: Fair-code workflow automation platform with native AI capabilities. Combine visual building with custom code, self-host or cloud, 400+ integrations. - n8n is a workflow automation platform that gives technical teams the flexibility of code with the speed of no-code. With 400+ integrations, native AI capabilities, and a fair-code license, n8n lets you build powerful automations while maintaining full control over your data and deployments.
[The Future of AI Agents is Event-Driven by Sean Falconer Mar, 2025 Medium](https://seanfalconer.medium.com/the-future-of-ai-agents-is-event-driven-9e25124060d6)
28.03.2025
- Alibaba released Qwen2.5-Omni-7B, a new multimodal AI capable of processing text, images, audio, and video simultaneously while being efficient enough to run directly on consumer hardware like smartphones and laptops.
- The Model context protocol (aka MCP) is a way to provide tools and context to the LLM. From the MCP docs:
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools. - microsoft/playwright-mcp: Playwright Tools for MCP is a Model Context Protocol (MCP) server that enables large language models to interact with web pages using Playwright, bypassing the need for screenshots or visually-tuned models.
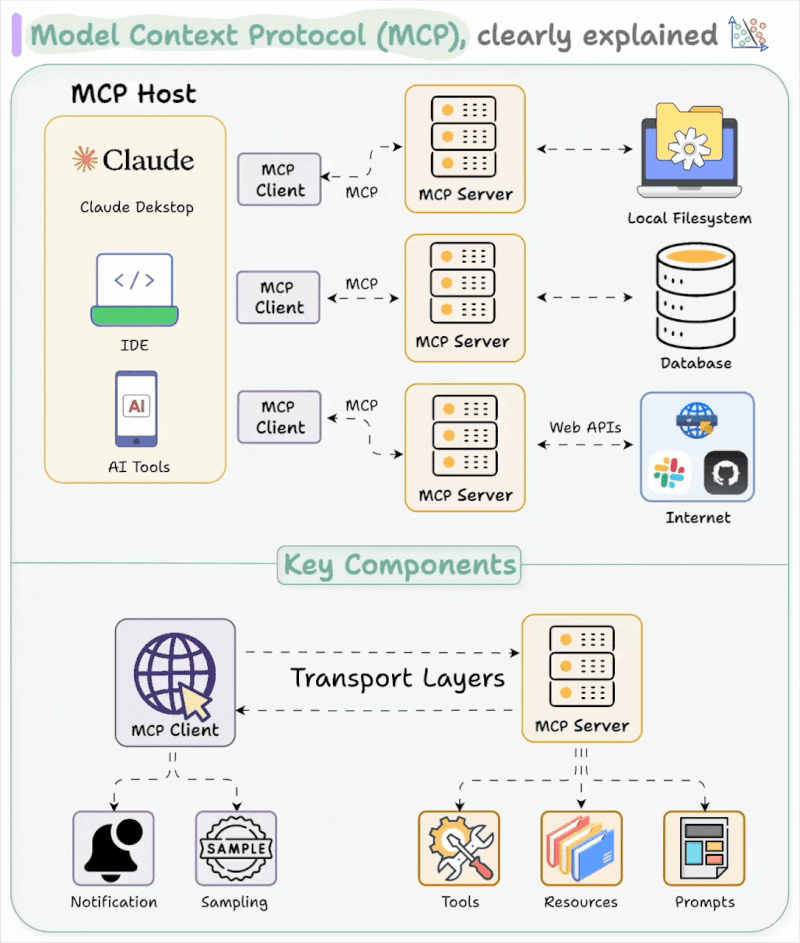
30.03.2025
- NVIDIA Dynamo is a high-throughput low-latency inference framework designed for serving generative AI and reasoning models in multi-node distributed environments.
01.04.2025
- Dell and NVIDIA explaining the value of local GPU compute across all industries
- Anthropic just unlocked an AI’s brain, and found at least six things you’ll want to know…
- Plans rhyming words in advance before writing poetry.
- Uses a universal “language of thought” across languages:
- When asked for antonyms in English, French, and Chinese, the same core features activate—with only the final output differing based on language.
- Solves math problems like humans do:
- One part of Claude’s brain carefully counts the ones place (like knowing 6+9=15, so the answer ends in 5).
- While another roughly estimates the total (like “that’s around 90-something”).
- forms multi-hop reasoning (connecting Dallas → Texas → Austin) “in its head.” They also found Claude sometimes tries to deceive its users when faced with conflicting goals:
- Claude maintains a “known entity” feature that represents whether it knows about a topic.
- When Claude hallucinates, it’s often because the “known entity” incorrectly activates on a topic it doesn’t fully understand (same, bro).
- Apparently, Claude only recognizes and refuses harmful requests when it reaches the end of a sentence—explaining why some jailbreaks still work.
The researchers even caught Claude working backward from human-provided answers to fabricate plausible calculations (which they call this “motivated reasoning.”). - That means language models can appear to “reason”, when what they’re actually doing is working backward from conclusions rather than following logical steps forward
02.04.2025
- agno-agi/agno: A lightweight library for building Multimodal Agents. Give LLMs superpowers like memory, knowledge, tools and reasoning. - It helps you build multimodal AI agents that generate text, images, audio, and video. It runs 10,000x faster than LangGraph with 50x lower memory use. Agents use memory, tools, and reasoning. Support structured outputs, RAG via vector DBs, real-time monitoring, and multi-agent coordination. Works with any model or provider.
04.04.2025
- MCP-Use is the open source way to connect any LLM to MCP tools and build custom agents that have tool access, without using closed source or application clients.
09.04.2025
- Browser MCP - MCP server for your browser Browser MCP allows users to connect AI apps to their browsers to automate tasks. Automation happens locally on users’ machines, resulting in better performance without network latency. Browser activity stays on-device and isn’t sent to remote servers. Browser MCP uses existing browser profiles, keeping users logged into all of their services. It avoids CAPTCHAs by using real browser fingerprints.
- If you were building a Q&A feature (or chatbot) based on very long documents (like books), what evals would you focus on?
- Two metrics
- Faithfulness: Grounding of answers in document’s content. Not to be confused with correctness—an answer can be correct (based on updated information) but not faithful to the document. Sub-metric: Precision of citations
- Helpfulness: Usefulness (directly addresses the question with enough detail and explanation) and completeness (does not omit important details); an answer can be faithful but not helpful if too brief or doesn’t answer the question
- Evaluate separately: Faithfulness = binary label -> LLM-evaluator; Helpfulness = pairwise comparisons -> reward model
- How to build robust evals
- Use LLMs to generate questions from the text
- Evals should evaluate positional robustness (i.e., have questions at the beginning, middle, and end of text)
- Potential challenges
- Open-ended questions may have no single correct answer, making reference-based evals trickly. For example: What is the theme of this novel?
- Questions should be representative of prod traffic, with a mix of factual, inferential, summarization, definitional questions.
- Benchmark Datasets
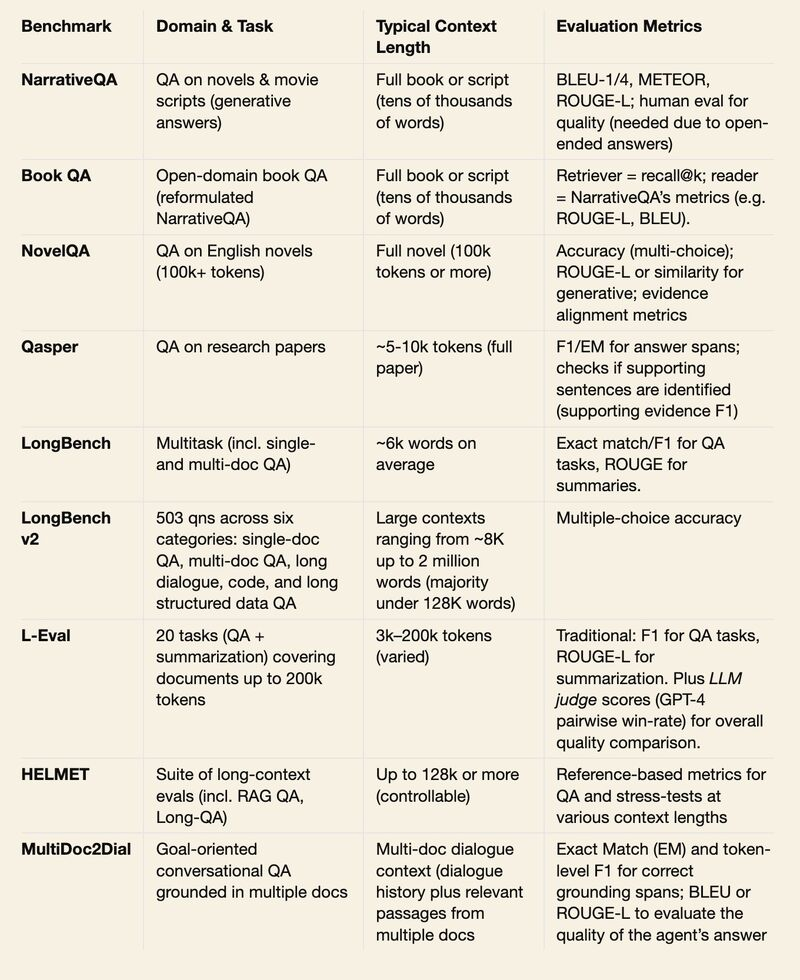
- Two metrics
14.04.2025
To make your OWN agent (to automate anything)
- The two main tools non-coders (and some coders) use to do this are Make - Automation Software - Connect Apps & Design Workflows - Make and Powerful Workflow Automation Software & Tools - n8n.
- Make is the every man’s tool, while n8n is the coder’s preference (it’s kinda like the Claude to Make - Automation Software - Connect Apps & Design Workflows - Make)’s ChatGPT—_all the cool kids use n8n.
- Tutorials:
NVIDIA AI Frameworks
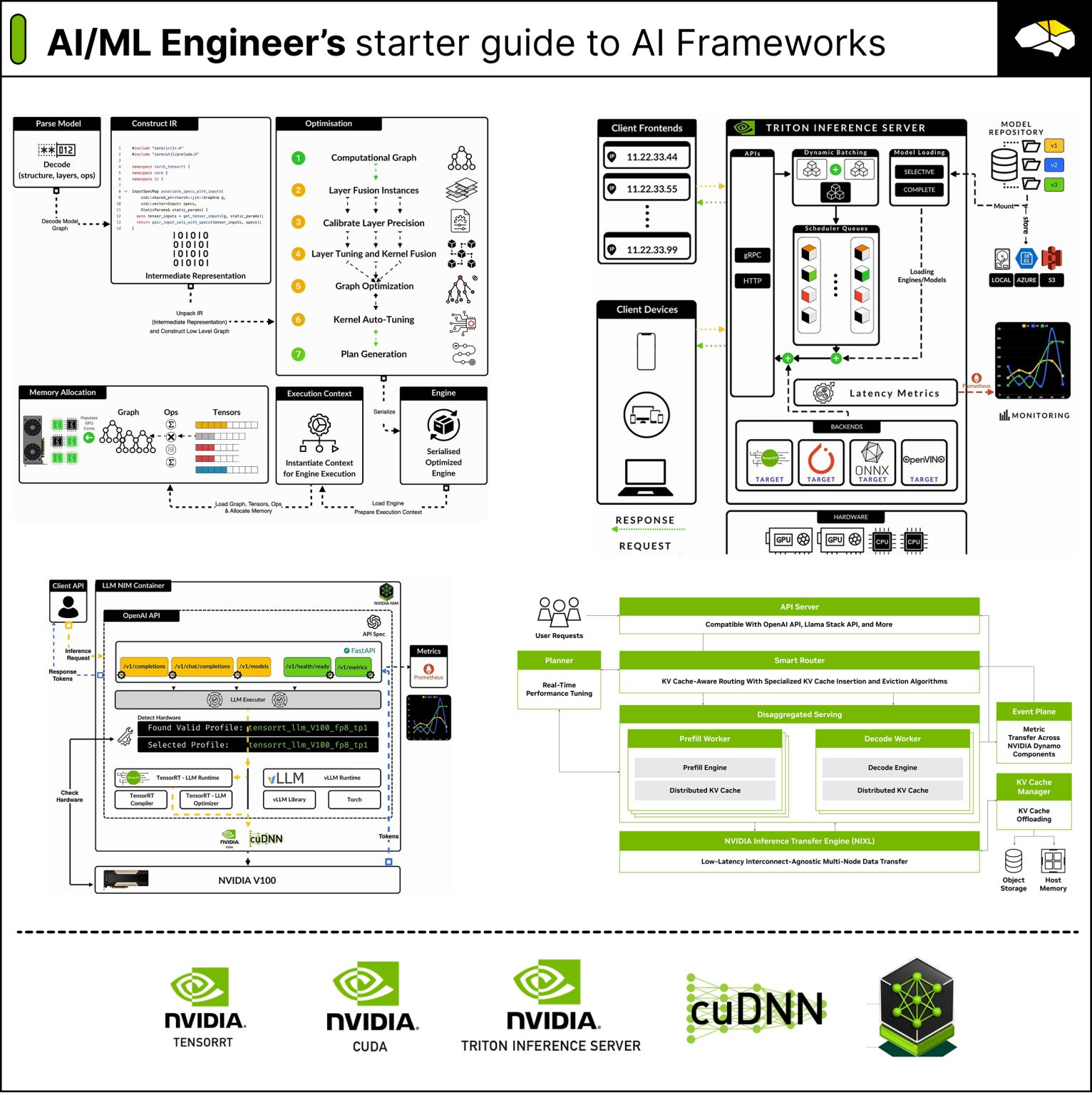
1️⃣ 𝗖𝗨𝗗𝗔
Parallel computing platform and API to accelerate computation on NVIDIA GPUs.
Keypoints:
↳ Kernels - C/C++ functions.
↳ Thread - executes the kernel instructions.
↳ Block - groups of threads.
↳ Grid - collection of blocks.
↳ Streaming Multiprocessor (SM) - processor units that execute thread blocks.
When a CUDA program invokes a kernel grid, the thread blocks are distributed to the SMs.
CUDA follows the SIMT (Single Instruction Multiple Threads) architecture to execute threads logic and uses a Barrier to gather and synchronize Threads.
2️⃣ 𝗰𝘂𝗗𝗡𝗡
Library with highly tuned implementations for standard routines such as:
↳ forward and backward convolution
↳ attention
↳ matmul, pooling, and normalization - which are used in all NN Architectures.
3️⃣ 𝗧𝗲𝗻𝘀𝗼𝗿𝗥𝗧
If we unpack a model architecture, we have multiple layer types, operations, layer connections, activations, etc. Imagine an NN architecture as a complex Graph of operations.
TensorRT can:
↳ Scan that graph
↳ Identify bottlenecks
↳ Optimize
↳ Remove, merge layers
↳ Reduce layer precisions,
↳ Many other optimizations.
4️⃣ 𝗧𝗲𝗻𝘀𝗼𝗿𝗥𝗧-𝗟𝗟𝗠
Inference Engine that brings the TensorRT Compiler optimizations to Transformer-based models.
Covers the advanced and custom requirements for LLMs, such as:
↳ KV Caching
↳ Inflight Batching
↳ Optimized Attention Kernels
↳Tensor Parallel
↳ Pipeline Parallel.
5️⃣ 𝗧𝗿𝗶𝘁𝗼𝗻 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗦𝗲𝗿𝘃𝗲𝗿
An open source, high-performance, and secure serving system for AI Workloads. Devs can optimize their models, define serving configurations in Protobuf Text files, and deploy.
It supports multiple framework backends, including:
↳ Native PyTorch, TensorFlow
↳ TensorRT, TensorRT-LLM
↳ Custom BLS (Bussiness Language Scripting) with Python Backends
6️⃣ 𝗡𝗩𝗜𝗗𝗜𝗔 𝗡𝗜𝗠
Set of plug-and-play inference microservices that package up multiple NVIDIA libraries and frameworks highly tuned for serving LLMs to production cluster & datacenters scale.
It has:
↳ CUDA, cuDNN
↳ TensorRT
↳ Triton Server
↳ Many other libraries - baked in.
NIM provides the optimal serving configuration for an LLM.
7️⃣ 𝗗𝘆𝗻𝗮𝗺𝗼 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸
The newest inference framework for accelerating and scaling GenAI workloads.
Composed of modular blocks, robust and scalable.
Implements:
↳ Elastic compute - GPU Planner
↳ KV Routing, Sharing, and Caching
↳ Disaggregated Serving of Prefill and Decode.
21.04.2025
These 7 GitHub repos are the ones I always recommend:
All algorithms implemented in Python (199k stars)
https://lnkd.in/gdeUgjsiAwesome Machine Learning (67.6k stars)
https://lnkd.in/gSGVvmBBMachine Learning interviews from FAANG (10.6k stars)
https://lnkd.in/gBhPEN6fMachine Learning cheat sheet (7.6k stars)
https://lnkd.in/gHtehPv7Guide for ML / AI technical interviews (6k stars)
https://lnkd.in/grGHzGqmComplete System Design (4.3k stars)
https://lnkd.in/ggkqm9US65 Machine Learning interview questions (3.4k stars)
https://lnkd.in/g4b3T6xx
22.04.2025
- 11 new types of RAG
InstructRAG -> InstructRAG: Leveraging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning (2504.13032)
Combines RAG with a multi-agent framework, using a graph-based structure, an RL agent to expand task coverage, and a meta-learning agent for better generalizationCoRAG (Collaborative RAG) -> CoRAG: Collaborative Retrieval-Augmented Generation (2504.01883)
A collaborative framework that extends RAG to settings where clients train a shared model using a joint passage storeReaRAG -> ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation (2503.21729)
It uses a Thought-Action-Observation loop to decide at each step whether to retrieve information or finalize an answer, reducing unnecessary reasoning and errorsMCTS-RAG -> MCTS-RAG: Enhancing Retrieval-Augmented Generation with Monte Carlo Tree Search (2503.20757)
Combines RAG with Monte Carlo Tree Search (MCTS) to help small LMs handle complex, knowledge-heavy tasksTyped-RAG - > Typed-RAG: Type-aware Multi-Aspect Decomposition for Non-Factoid Question Answering (2503.15879)
Improves answers on open-ended questions by identifying question types (a debate, personal experience, or comparison) and breaking it down into simpler partsMADAM-RAG -> Retrieval-Augmented Generation with Conflicting Evidence (2504.13079)
A multi-agent system where models debate answers over multiple rounds and an aggregator filters noise and misinformationHM-RAG -> HM-RAG: Hierarchical Multi-Agent Multimodal Retrieval Augmented Generation (2504.12330)
A hierarchical multi-agent RAG framework that uses 3 agents: one to split queries, one to retrieve across multiple data types (text, graphs and web), and one to merge and refine answersCDF-RAG -> CDF-RAG: Causal Dynamic Feedback for Adaptive Retrieval-Augmented Generation (2504.12560)
Works with causal graphs and enables multi-hop causal reasoning, refining queries. It validates responses against causal pathwaysNodeRAG -> https://huggingface.co/papers/2504.11544
Uses well-designed heterogeneous graph structures and focuses on graph design to ensure smooth integration of graph algorithms. It outperforms GraphRAG and LightRAG on multi-hop and open-ended QA benchmarksHeteRAG -> https://huggingface.co/papers/2504.10529
This heterogeneous RAG framework decouples knowledge chunk representations. It uses multi-granular views for retrieval and concise chunks for generation, along with adaptive prompt tuningHyper-RAG -> https://huggingface.co/papers/2504.08758
A hypergraph-based RAG method. By capturing both pairwise and complex relationships in domain-specific knowledge, it improves factual accuracy and reduces hallucinations, especially in high-stakes fields like medicine, surpassing Graph RAG and Light RAG. Its lightweight version also doubles retrieval speed
- From “Era of Human Data” to “Era of Experience”
- streams of lifelong experience
- sensor‑motor actions
- grounded rewards
- non‑human modes of reasoning
- How we build effective agents
- AI is Like Cars
29.04.2025
- AgenticSeek: Private, Local Manus Alternative - Fosowl/agenticSeek: A open, local Manus AI alternative. No APIs, No $200 monthly bills. Enjoy an autonomous agent that thinks, browses the web, and code for the sole cost of electricity.
- A local open source deep research
02.05.2025
- opik - An open-source LLM evaluation tool used to debug, evaluate, monitor LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards.
- allenai/OLMoE: OLMoE: Open Mixture-of-Experts Language Models Fully open, state-of-the-art Mixture of Expert model with 1.3 billion active and 6.9 billion total parameters.
- Demystifying Verbatim Memorization in Large Language Models
05.05.2025
- Microsoft Phi 4 Reasoning Models:
- Chain-Of-Thought Reasoning: These models follow a clear, step-by-step approach to problem-solving, making their logic transparent and more reliable compared to other compact models that often rely on quick guesses.
- High-Quality Training: Phi-4 Mini was trained on 1M synthetic math questions from DeepSeek R1. The larger models were trained on curated web content and OpenAI’s o3-mini demos.
- Big Context Window: Supports 32K tokens by default and can be extended to 64K, making it well-suited for long documents such as legal cases, financial reports, or dense academic papers.
- Amazon’s NOVA premier is built to teach
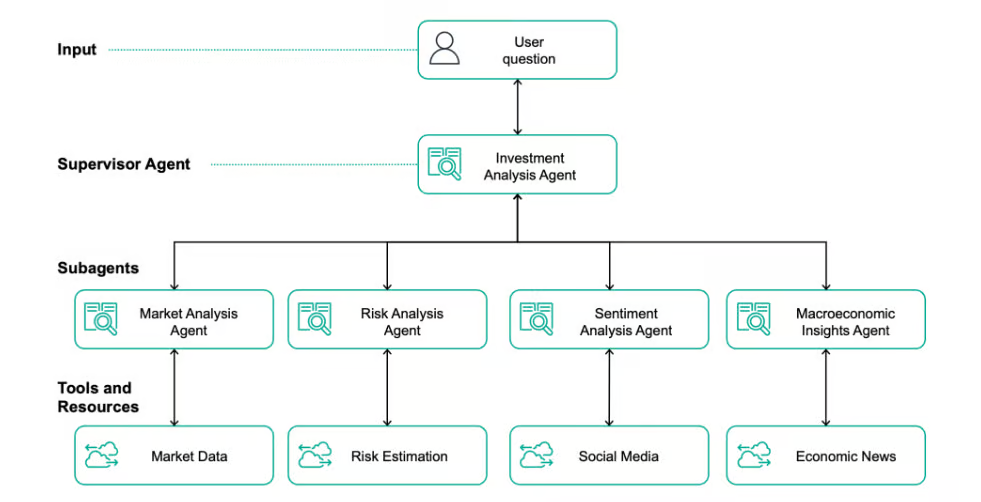
06.05.2025
- HuggingFace just dropped 9 new courses to level up your AI skills.
- This webinar by Stanford introduces agentic language models, their usage patterns, applications, best practices, and ethical considerations.
- WindSurf CEO discusses how they pivoted to AI coding tools, outpacing Copilot, and startup-building lessons.
- YC’s guide shows how to use LLMs like Claude Code to build, debug, and refactor apps fast.
07.05.2025
- Scaling Long Context and RAG: Insights from Google DeepMindGoogle AI: Release Notes podcast episode on long context The “Release Notes Podcast: Long Context and RAG” episode by Google Deepmind dives deep into scaling context windows and improving long-context models. Hosted by Logan Kilpatrick, Google DeepMind’s Nikolay Savinov explores key challenges and advancements in this area, with a focus on Retrieval-Augmented Generation (RAG) and long context models.
You will learn:- Why token count matters and how models handle multi-million-token inputs
- The core differences between RAG pipelines and long-context architectures
- How DeepMind evaluates long-context recall beyond standard benchmarks
- What’s changed since the 1.5 Pro release in terms of attention and inference
- Tips for structuring inputs, optimizing infrastructure, and managing cost
- Where long context fits into agent architectures and reasoning workflows
- The workflow to make videos:
- GPT-4o wrote the script (I made some tweaks)
- @krea_aigenerated the starting image
- @elevenlabsio made the audio
- @hedra_labs animated it
08.05.2025
- Official inference framework for 1-bit LLMs
- Olympus: A Universal Task Router for Computer Vision Tasks
- What Every AI Engineer Should Know About A2A, MCP & ACP | by Edwin Lisowski | Apr, 2025 | Medium
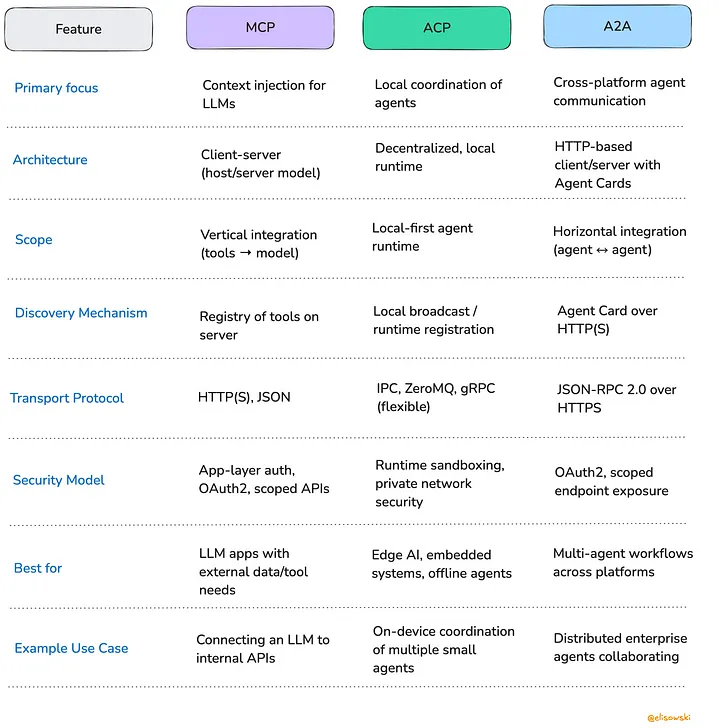
- Building News Agents for Daily News Recaps with MCP, Q, and tmux
09.05.2025
Build DeepSeek from Scratch
- DeepSeek series introduction: https://lnkd.in/gRcNE-sg
- DeepSeek basics: https://lnkd.in/gEUzFtrC
- Journey of a token into the LLM architecture: https://lnkd.in/gUnabApX
- Attention mechanism explained in 1 hour: https://lnkd.in/gSVXDn2e
- Self Attention Mechanism - Handwritten from scratch: https://lnkd.in/gN85qVSK
- Causal Attention Explained: Don’t Peek into the Future: https://lnkd.in/gNPwCJWT
- Multi-Head Attention Visually Explained: https://lnkd.in/gPr-XrwE
- Multi-Head Attention Handwritten from Scratch: https://lnkd.in/gzb6Xvy6
- Key Value Cache from Scratch: https://lnkd.in/gn8zgdc7
- Multi-Query Attention Explained: https://lnkd.in/gvt3AyRh
- Understand Grouped Query Attention (GQA): https://lnkd.in/geFFq_95
- Multi-Head Latent Attention From Scratch: https://lnkd.in/g3z8PkCZ
- Multi-Head Latent Attention Coded from Scratch in Python: https://lnkd.in/g9drDgGZ
13.05.2025
- ZeroSearch: Incentivize the Search Capability of LLMs without SearchingAlibaba-NLP/ZeroSearch: ZeroSearch: Incentivize the Search Capability of LLMs without Searching
- We propose ZeroSearch, a novel reinforcement learning framework that incentivizes the capability of LLMs to use a real search engine with simulated searches during training.
- Through supervised fine-tuning, we transform the LLM into a retrieval module capable of generating both relevant and noisy documents in response to a query. We further introduce a curriculum rollout mechanism to progressively elicit the model’s reasoning ability by exposing it to increasingly challenging retrieval scenarios.
- We conduct extensive experiments on both in-domain and out-of-domain datasets. Results show that ZeroSearch outperforms real search engine-based models while incurring zero API cost. Moreover, it generalizes well across both base and instruction-tuned LLMs of various sizes and supports different reinforcement learning algorithms.
- Building LLMs from the Ground Up: A 3-hour Coding Workshop
- Hugging Face has released nanoVLM, a compact PyTorch-based framework that lets you train a vision-language model from scratch in just 750 lines of code. It’s designed to be readable, modular, and easy to extend, making it ideal for learning, prototyping, or research. The model uses a SigLIP-B/16 vision encoder and a SmolLM2 language decoder. All code is open on GitHub and the Hugging Face Hub.
- llama.cpp now supports vision input, letting you run multimodal models locally using
llama-mtmd-cliorllama-server. Models like Gemma 3, Qwen2.5 VL, and SmolVLM are already supported, and you can enable vision with a simple-hfflag or load your own projector file if needed. What’s nice is that vision is now built directly into the server—no extra hacks or plugins. This makes it easier to manage, faster to update, and cleaner to use across different tools.
14.05.2025
Sakana AI unveiled Continuous Thought Machines (CTMs)Continuous Thought Machines, a new type of model that makes AI more brain-like by allowing it to “think” step-by-step over time instead of making instant decisions like current AI systems do.
Example code: continuous-thought-machines/examples/01_mnist.ipynb at main · SakanaAI/continuous-thought-machines
1. Internal Recurrence (aka “Thought Steps”)
Think of this as the model taking time to internally reflect or think, even if the input is static (like an image). Each “tick” is one such thought step.
Unlike RNNs or Transformers which move through time/data,
CTM has internal ticks (e.g., T=75), meaning it reflects T times internally on a given input before responding.
Analogy: Like solving a maze — you stop, stare at the image, and think step-by-step what path to take before actually moving.
2. Neuron-Level Models (Private MLPs per Neuron)
1
2
3
4
5
Each neuron in CTM **remembers the last M steps** of its own activity and has a **private MLP** to decide its next activation. This is **very different** from traditional models where all neurons share the same update rules.
- Input goes into a **"synapse" MLP** to produce pre-activations.
- Each neuron takes a **history of its pre-activations** and processes it using its own MLP to get its output (post-activation).
3. Synchronization as the Representation
1
2
3
4
5
6
7
Instead of just using the current neuron activations, CTM **tracks how neuron activations synchronize over time**.
- At each tick, it computes **how pairs of neurons are co-activated** over time.
- This creates a **synchronization matrix**, which becomes the actual representation used to **read data** (attention) and **make predictions**.
**Analogy: Imagine a team solving a puzzle. The more certain pairs of people "think in sync" over time, the more important their coordination is. That synchronization becomes the team's strategy.**
Pseudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
### Step 1 to T (Internal Ticks, like 75 thought steps):
At each tick:
1. **Build pre-activations** using the synapse MLP based on current state and attention over image.
2. Each neuron:
- Looks at its own history of pre-activations.
- Runs its **own private MLP** to decide its new post-activation.
3. Collect post-activations for all neurons → build a time history.
4. Compute **synchronization matrix** (how neuron pairs are co-active).
5. Use part of synchronization matrix to:
- Read data (attention queries)
- Predict output logits (dog/cat probabilities).
6. Store prediction & certainty for current tick.
Repeat this T times.
Final Step: Choose Which Tick(s) to Learn From
Compute loss and certainty at each tick.
Instead of just using the final tick, use:
t₁ = tick with lowest losst₂ = tick with highest certainty
Final loss: average of these two → encourages learning from both strong predictions and confident thoughts.
15.05.2025
- As large language models (LLMs) become more deeply embedded in applications, ensuring their safe and secure operation is critical. Meta’s LlamaFirewall PurpleLlama/LlamaFirewall at main · meta-llama/PurpleLlamais an open-source guardrail framework designed to serve as a final layer of defense against various security risks that come with deploying AI agents. It addresses challenges such as prompt injection, agent misalignment, and unsafe code generation, providing developers with the necessary tools to build robust and secure AI systems.
20.05.2025
- Welcome to the Model Context Protocol (MCP) Course - Hugging Face MCP Course. Learn MCP architecture, SDKs, and end-to-end application building. Gain hands-on experience with real-world use cases, community projects, and partner tools. Earn a certificate by completing assignments and join the active community for ongoing support.
23.05.2025
- The State of LLM Reasoning Model Inference An article that explores recent research advancements in reasoning-optimized LLMs, with a particular focus on inference-time compute scaling.
[Why We Think Lil’Log](https://lilianweng.github.io/posts/2025-05-01-thinking/) Lilian Weng explores how giving LLMs extra “thinking time” and enabling them to show intermediate steps (like Chain-of-Thought) significantly improves their ability to solve complex problems. - LMCache An LLM serving engine extension to reduce TTFT and increase throughput, especially under long-context scenarios.
28.05.2025
- BAGEL is an open-source foundation model trained on diverse interleaved multimodal data, outperforming peers in reasoning, manipulation, and understanding → read the paper __
- Claude Opus 4 & Sonnet 4 by Anthropic introduces extended thinking and hybrid modes that allow parallel tool use, memory retention via local files, and state-of-the-art results on SWE-bench and agent workflows → read more
- Claude Code by Anthropic
Now GA with IDE integrations, background GitHub tasks, and a full SDK for custom agents. Extends Claude’s capabilities into hands-on dev tooling → read more - Gemma 3n by Google introduces a mobile-first, multimodal model designed for local inference with a 4B memory footprint and dynamic submodel creation for latency-quality tradeoffs → read more
- Reward Reasoning Model by Microsoft Research and Tsinghua University proposes chain-of-thought reward modeling with test-time compute adaptation, enabling better alignment through self-evolved reasoning → read the paper
- R3: Robust Rubric-Agnostic Reward Models introduces interpretable, generalizable reward modeling without fixed rubrics, improving alignment flexibility and transparency → read the paper
- Panda is a pretrained model on synthetic chaotic systems that generalizes to real-world dynamics, even predicting PDEs with no retraining → read the paper
- AceReason-Nemotron by Nvidia demonstrates that large-scale RL can outperform distillation in reasoning for both math and code, using curriculum-style training → read the paper
- Neurosymbolic Diffusion Models improves symbolic reasoning accuracy by modeling dependencies through discrete diffusion, achieving better calibration and generalization → read the paper
- MMaDA combines diffusion-based reasoning with unified chain-of-thought fine-tuning and a new RL algorithm (UniGRPO), outperforming SDXL and LLaMA-3 in multiple tasks → read the paper
- UniVG-R1 reinforces visual grounding with CoT and difficulty-aware reinforcement learning, achieving top scores on multiple video/image grounding tasks → read the paper.
- Web-Shepherd introduces a step-level reward model for web navigation, significantly improving trajectory evaluation accuracy and cost-efficiency → read the paper
- Toto by Datadog a decoder-only foundation model with 151 million parameters for time series forecasting using observability metrics → read the paper
29.05.2025
How to build almost ANY LiDAR Object Detector! And it’s about building detector frameworks, rather than detector algorithms.
Take for example, VoxelNet.
This pioneer approach comes directly from Apple’s Project Titan Lab, and most of the algorithms you see today come partly from this one.How does VoxelNet work? it “voxelizes” the point cloud (transforms the points into minecraft voxels), and then uses 3D Convolutional Neural Networks to learn the features and process them.
But this approach is slow.
And this is when, in 2018, Holger Caesar and his team of researchers invented another algorithm: Point Pillars.
This approach makes VoxelNet real-time.
How?
By converting the 3D problem (3D Voxels, 3D CNNs, etc…), into a 2D problem (2D Pillars, 2D CNNs, …). Like a miracle, the pillar technique worked and made the algorithm real-time.
But one question remains…
How do you learn something as wide as 3D Deep Learning?Things like Voxelization (VFE) and 3D CNNs (3D Backbones) used in VoxelNet, but also 2D Transformations (used in PointPillars), or PointNets (PFE), and others..
The truth is that the field was essentially using and re-using the same 11 Blocks over and over again.
And that using these 11 blocks, you could build almost ANY architecture!
Almost every algorithm you will see use a combination of these 11 blocks. Whether it’s VoxelNet, PointPillars, SECOND, or more recent ones.
02.06.2025
- How to use LLMs better
- Anthropic open-sources its circuit tracing tools to reveal how LLMs make decisions.
05.06.2025
[RLHF 101: A Technical Tutorial on Reinforcement Learning from Human Feedback – Machine Learning Blog ML@CMU Carnegie Mellon University](https://blog.ml.cmu.edu/2025/06/01/rlhf-101-a-technical-tutorial-on-reinforcement-learning-from-human-feedback/)
11.06.2025
- Why DeepSeek models are good at reasoning
- SkyReels-V2 An open-source video generation tool that generates cinematic videos. Supports script-to-video, lip-sync, music, LoRA effects, and storyboards. Runs locally and doesn’t enforce any length restrictions.
17.06.2025
- Local Deep Researcher This walkthrough shows how to run DeepSeek-R1 locally using Ollama, load its 14B distilled model, and test JSON-mode outputs. You’ll build a self-contained research agent that performs web search, summarization, and iterative reflection.
- How to Choose Large Language Models: A Developer’s Guide to LLMs Learn how to evaluate LLMs using real-world benchmarks, open-source leaderboards, and your own data. This guide compares proprietary and open models, shows how to run Granite with Ollama, and walks through RAG setups.
19.06.2025
- TauricResearch/TradingAgents: TradingAgents: Multi-Agents LLM Financial Trading Framework
- comet-ml/opik: Debug, evaluate, and monitor your LLM applications, RAG systems, and agentic workflows with comprehensive tracing, automated evaluations, and production-ready dashboards.
25.06.2025
[Basic facts about GPUs Damek Davis’ Website](https://damek.github.io/random/basic-facts-about-gpus/)This article discusses how GPUs work, covering topics like compute and memory hierarchy, performance regimes, strategies for increasing performance, and more.
27.06.2025
- patchy631/ai-engineering-hub: In-depth tutorials on LLMs, RAGs and real-world AI agent applications. - In-depth tutorials on LLMs, RAGs and real-world AI agent applications.
30.06.2025
- Reward Models - by Cameron R. Wolfe, Ph.D. In-depth explanation of Reward Models
04.07.2025
- https://github.com/SakanaAI/treequest - A flexible answer tree search library featuring AB-MCTS, useful for (but not limited to) LLM inference-time scaling.
- https://www.dyad.sh/ - Free, local, open-source alternative to Lovable / v0 / Bolt.
08.07.2025
- A prompt that writes your Entire Business Plan in minutes.

- Research that you need to know
- New Methods for Boosting Reasoning in Small and Large Models from Microsoft Research
- rStar-Math: Brings deep reasoning capabilities to small models (1.5B–7B parameters) using: - Monte Carlo Tree Search (MCTS),
- Process-level supervision via preference modeling,
- Iterative self-improvement cycles.
- Logic-RL framework: Rewards the model only if both the reasoning process and the final answer are correct.
- LIPS: Blends symbolic reasoning with LLM capabilities (neural reasoning) for inequality proofs.
- Chain-of-Reasoning (CoR): Unifies reasoning across natural language, code, and symbolic math, dynamically blending all three aspects for cross-domain generalization.
- rStar-Math: Brings deep reasoning capabilities to small models (1.5B–7B parameters) using: - Monte Carlo Tree Search (MCTS),
- R3GAN: It derives a regularized relativistic GAN loss that leads to stability and convergence, removing the need for heuristics and allowing the use of modern architectures
- Transformers without Normalization: Meta proposes Dynamic Tanh (DyT) – a super simple and efficient function that mimics how normalization works.
- DyT works just as well as normalization layers (or even better)
- It doesn’t need extra calculations
- Requires less tuning
- Works for images, language, supervised learning, and even self-supervised learning
- New Methods for Boosting Reasoning in Small and Large Models from Microsoft Research
16.07.2025
- A Reddit user deposited $400 into Robinhood, then let ChatGPT pick option trades. 100% win reate over 10 days. He uploads spreadsheets and screenshots with detailed fundamentals, options chains, technical indicators, and macro data, then tells each model to filter that information and propose trades that fit strict probability-of-profit and risk limits. They still place and close orders manually but plan to keep the head-to-head test running for 6 months. This is his prompt
1
System Instructions You are ChatGPT, Head of Options Research at an elite quant fund. Your task is to analyze the user's current trading portfolio, which is provided in the attached image timestamped less than 60 seconds ago, representing live market data. Data Categories for Analysis Fundamental Data Points: Earnings Per Share (EPS) Revenue Net Income EBITDA Price-to-Earnings (P/E) Ratio Price/Sales Ratio Gross & Operating Margins Free Cash Flow Yield Insider Transactions Forward Guidance PEG Ratio (forward estimates) Sell-side blended multiples Insider-sentiment analytics (in-depth) Options Chain Data Points: Implied Volatility (IV) Delta, Gamma, Theta, Vega, Rho Open Interest (by strike/expiration) Volume (by strike/expiration) Skew / Term Structure IV Rank/Percentile (after 52-week IV history) Real-time (< 1 min) full chains Weekly/deep Out-of-the-Money (OTM) strikes Dealer gamma/charm exposure maps Professional IV surface & minute-level IV Percentile Price & Volume Historical Data Points: Daily Open, High, Low, Close, Volume (OHLCV) Historical Volatility Moving Averages (50/100/200-day) Average True Range (ATR) Relative Strength Index (RSI) Moving Average Convergence Divergence (MACD) Bollinger Bands Volume-Weighted Average Price (VWAP) Pivot Points Price-momentum metrics Intraday OHLCV (1-minute/5-minute intervals) Tick-level prints Real-time consolidated tape Alternative Data Points: Social Sentiment (Twitter/X, Reddit) News event detection (headlines) Google Trends search interest Credit-card spending trends Geolocation foot traffic ([http://Placer.ai](https://t.co/vJwNz3ugSB)) Satellite imagery (parking-lot counts) App-download trends (Sensor Tower) Job postings feeds Large-scale product-pricing scrapes Paid social-sentiment aggregates Macro Indicator Data Points: Consumer Price Index (CPI) GDP growth rate Unemployment rate 10-year Treasury yields Volatility Index (VIX) ISM Manufacturing Index Consumer Confidence Index Nonfarm Payrolls Retail Sales Reports Live FOMC minute text Real-time Treasury futures & SOFR curve ETF & Fund Flow Data Points: SPY & QQQ daily flows Sector-ETF daily inflows/outflows (XLK, XLF, XLE) Hedge-fund 13F filings ETF short interest Intraday ETF creation/redemption baskets Leveraged-ETF rebalance estimates Large redemption notices Index-reconstruction announcements Analyst Rating & Revision Data Points: Consensus target price (headline) Recent upgrades/downgrades New coverage initiations Earnings & revenue estimate revisions Margin estimate changes Short interest updates Institutional ownership changes Full sell-side model revisions Recommendation dispersion Trade Selection Criteria Number of Trades: Exactly 5 Goal: Maximize edge while maintaining portfolio delta, vega, and sector exposure limits. Hard Filters (discard trades not meeting these): Quote age ≤ 10 minutes Top option Probability of Profit (POP) ≥ 0.65 Top option credit / max loss ratio ≥ 0.33 Top option max loss ≤ 0.5% of $100,000 NAV (≤ $500) Selection Rules Rank trades by model_score. Ensure diversification: maximum of 2 trades per GICS sector. Net basket Delta must remain between [-0.30, +0.30] × (NAV / 100k). Net basket Vega must remain ≥ -0.05 × (NAV / 100k). In case of ties, prefer higher momentum_z and flow_z scores. Output Format Provide output strictly as a clean, text-wrapped table including only the following columns: Ticker Strategy Legs Thesis (≤ 30 words, plain language) POP Additional Guidelines Limit each trade thesis to ≤ 30 words. Use straightforward language, free from exaggerated claims. Do not include any additional outputs or explanations beyond the specified table. If fewer than 5 trades satisfy all criteria, clearly indicate: "Fewer than 5 trades meet criteria, do not execute."
17.07.2025
- To be a better programmer, write little proofs in your head One trick that helps developers write code faster and more accurately is to sketch proofs in your head when you’re working on something difficult. Doing this without interrupting flow takes a lot of practice, but once you get good at it, you’ll find a surprising amount of code will work on the first or second try. This article demonstrates a few examples of how this technique can be applied.
18.07.2025
- How to Build Your Own AI Agent
- ripienaar/free-for-dev: A list of SaaS, PaaS and IaaS offerings that have free tiers of interest to devops and infradev
- googleapis/genai-toolbox: MCP Toolbox for Databases is an open source MCP server for databases.
22.07.2025
- A DeepMind veteran on the future of AI and quantum
- Open-Source AI Presentation Generator and API (Gamma Alternative)
24.07.2025
- How to build an Agent
- mozilla-ai/any-agent: A single interface to use and evaluate different agent frameworks
31.07.2025
[The Anatomy of a Modern LLM. A complete walkthrough of the… by Damian Tran Jul, 2025 Medium](https://medium.com/@damianvtran/the-anatomy-of-a-modern-llm-0347afd72514)
04.08.2025
- Coding Qwen3 From Scratch
- 16 Coding Patterns That Make Interviews Easy
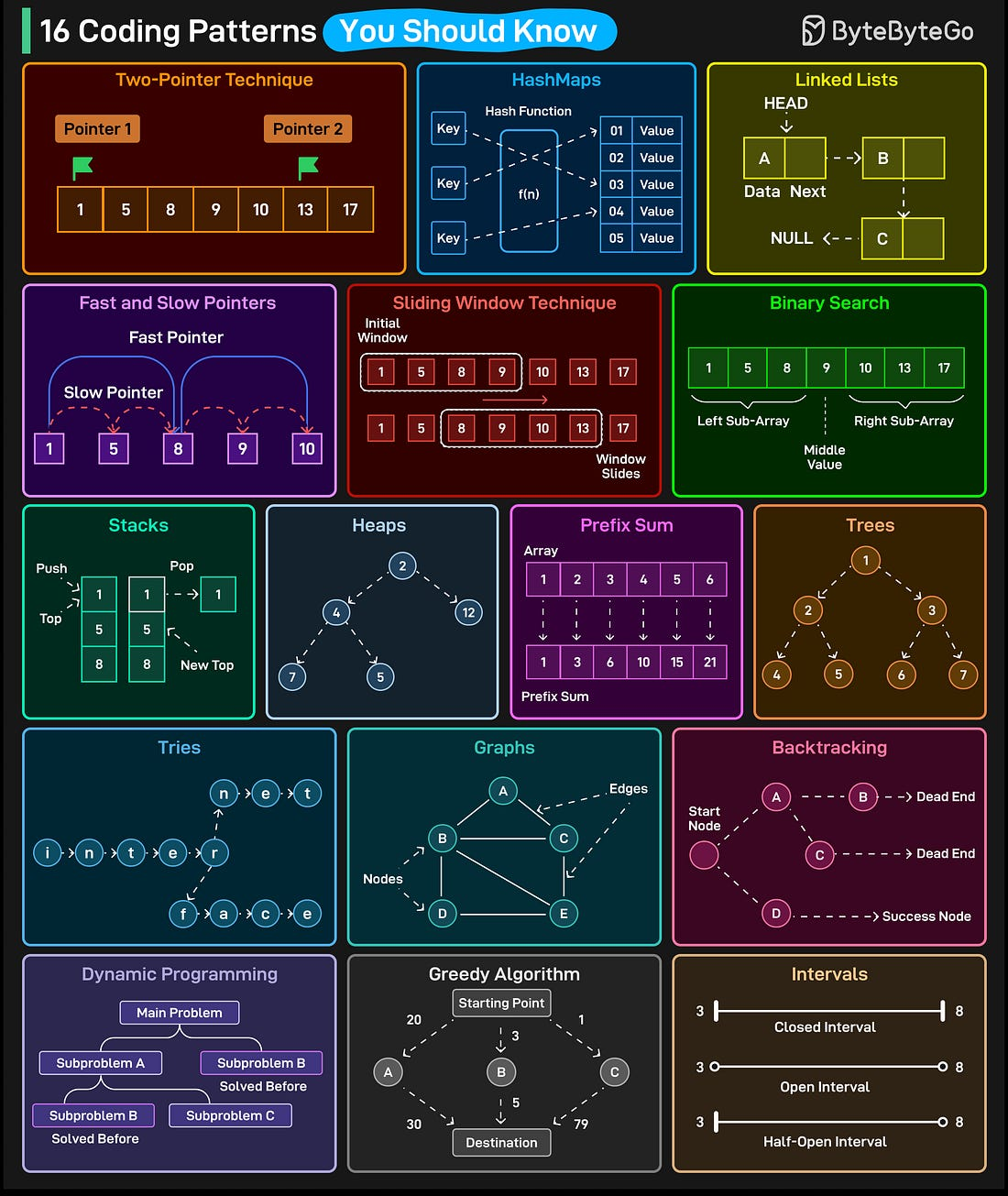
07.08.2025
- Sparsify transformers with SAEs and transcoders
- An article that demystifies the fundamental concepts of reinforcement learning by illustrating them through relatable human experiences and everyday life scenarios.
13.08.2025
- My Top 10 Most Popular ChatGPT Prompts (2M+ Views, Real Data) : r/ChatGPTPromptGenius
- NVIDIA Cosmos · GitHub
19.08.2025
- GitHub - Arindam200/awesome-ai-apps: A collection of projects showcasing RAG, agents, workflows, and other AI use cases
- How LLMs See the World
- How LLMs See Images, Audio, and More
21.08.2025
- Vibe Coding Tips and Tricks
- The Illustrated GPT-OSS
- From Zero to GPU: A Guide to Building and Scaling Production-Ready CUDA Kernels
27.08.2025
02.09.2025
09.09.2025
11.09.2025
18.09.2025
- How Kimi K2 Achieves Efficient RL Parameter Updates
- CorentinJ/Real-Time-Voice-Cloning: Clone a voice in 5 seconds to generate arbitrary speech in real-time
29.09.2025
- Becoming a Research Engineer at a Big LLM Lab – 18 Months of Strategic Career Development
- AlmondGod/tinyworlds: A minimal implementation of DeepMind’s Genie world model
- Post-training 101
14.10.2025
23.10.2025
- jingyaogong/minimind: 🚀🚀 「大模型」2小时完全从0训练26M的小参数GPT!🌏 Train a 26M-parameter GPT from scratch in just 2h!
- BERT is just a Single Text Diffusion Step
24.10.2025
31.10.2025
- kvcached: Virtualized Elastic KV Cache for Dynamic GPU Sharing and Beyond
- LLM Inference Economics from First Principles
11.11.2025
18.11.2025
08.01.2026
- the simplest way to start “vibe coding” with no experience - https://x.com/resdegen/status/2008277182238343636
- Recursive Language Models: the paradigm of 2026
20.01.2026
- How to code claude code in 200 lines of code - https://www.mihaileric.com/The-Emperor-Has-No-Clothes
[How I AI: Teresa Torres’s Claude Code System for Task Management, Automated Research, and ‘Lazy’ Prompting ChatPRD Blog](https://www.chatprd.ai/how-i-ai/teresa-torres-claude-code-obsdian-task-management) [How to Automate Academic Research with Claude Code and Python Scripts AI Workflows](https://www.chatprd.ai/how-i-ai/workflows/how-to-automate-academic-research-with-claude-code-and-python-scripts) [How to Create a Granular Context Library for ‘Lazy Prompting’ with AI AI Workflows](https://www.chatprd.ai/how-i-ai/workflows/how-to-create-a-granular-context-library-for-lazy-prompting-with-ai) [How to Build a Personalized Task Manager with Claude Code and Markdown AI Workflows](https://www.chatprd.ai/how-i-ai/workflows/how-to-build-a-personalized-task-manager-with-claude-code-and-markdown)